[toc]
A Survey on Temporal Action Localization
摘要:在计算机视觉中,时间动作定位是视频理解中最关键也是最具挑战性的问题之一。由于其广泛的应用,近年来引起了广泛的关注日常生活应用。时间动作定位技术已经取得了很大的进展,特别是最近深度学习的发展。而且在未裁剪的情况下,现在需要更多的时间动作定位视频。在这篇论文中,我们的目标是调查最新的技术和模型的视频时间行动定位。主要包括相关技术、一些基准数据集和评价时间动作定位的度量。此外,我们从两个方面总结了时间动作定位各方面:全监督学习和弱监督学习。并列举了几部具有代表性的作品并比较他们各自的表现。最后,对其进行了深入分析,并提出了发展前景研究方向,并总结调查。
关键词:动作检测,计算机视觉,全监督学习,时间动作定位,弱监督学习。
1.引言
随着视频数量急剧的增长,视频理解成为了计算机视觉领域的一个热点问题和具有挑战性的方向。这个视频理解发个信包括许多子研究方向,包括在夏威夷,被CVPR举办的ActivityNet 挑战2017,这个网络一共提出了5个任务。
- 未裁剪的视频分类(Untrimmed Video Classification )
- 裁剪后的行动识别( Trimmed Action Recognition)
- 时间动作检测( Temporal Action Proposals)
- 时间动作定位(Temporal Action Localization)
- 视频中密集的字幕事件(Dense-Captioning Events in Videos)
在最近的调查中,我们关注的是时间动作定位,也就是上面列出的第四个。它需要检测包含目标动作的时间间隔。对于长时间的未裁剪的视频,时间动作定位主要解决两个任务,识别和定位。特别是,a)动作发生的起始时间和终止时间,b)每个提案的类别是什么属于(如挥手、爬山、扣篮)。当然,一个视频可能包含一个或多个行动剪辑(action clips),所以时间动作定位是要开发模型和技术来提供计算机视觉应用所需要的最基本的信息:动作是什么,动作什么时候发生?我们将这个任务作为动作定位,或时间动作定位,或动作检测。
虽然动作识别和动作本地化都是视频理解里面很重要的任务,但是时间动作定位比动作识别更加具有挑战性。动作识别和动作定位的关系和图像检测类似于图像识别和图像检测。但是由于时间连续信息(temporal series information),时间动作定位比图像检测更见困难。困难主要来自以下几个方面:a)时间信息,由于1维时间连续信息,时间动作定位不能使用静态图片信息,它必须结合时间连续信息。b)与目标检测不同的是,边界对象通常是非常清晰的,所以我们可以为对象标记一个更清晰的边界框。然而,可能没有关于动作的确切时间范围合理定义,所以,不可能给一个动作开始和结束的准确边界。c)大的时间跨度,时间动作片段的跨度可以是非常大的,比如,挥手可能只几秒钟但是攀岩和骑自行车能够持续十几秒。它们时间跨度在长度上的不同,是的提取检测(extract proposals)很困难。另外,在开放的环境当中,这里也又许多问题,例如多尺度,多目标和相机移动。
时间动作定位非常贴近我们的生活,它具有广泛的应用前景和社会价值在视频概况(video summarization)、公共视频监控、技能评估和日常生活安全。所以它在最最近几年得到了广泛的关注。与“动作检测”有关的出版物总数约为324127份,近二十年来包括书籍、期刊、论文、会议论文、专利和一些科技成果。下面我们主要分析出版学术和回忆论文的趋势动作检测,如同图1所示
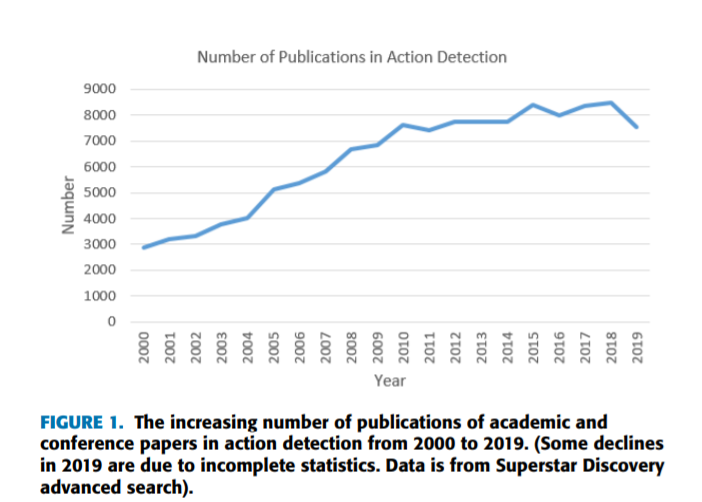
本调查旨在帮助对时态动作本地化感兴趣的初学者。它提供一个概括动作定位的方法和最新进展,本文余下部分组织如下。
- 第二节概述相关技术。
- 第三节介绍基本的时间动作定位数据集
- 第四节描述模型的性能评估指标
- 第五节从全监督和弱监督两方面,提供一个时间动作定位模型和方法的概述
- 第六节讨论现在的挑战和建议未来的方向
- 第七节总结本论文
2.相关技术
因为最近时间本地化已经成为了一个活跃的研究领域,许多解决此问题的不同的方法被提出。虽然动作检测已经研究了许多年,但是它仍处于实验室数据集的测试阶段,没有实际的实用性和工业化。理解视频中动作发生的时间和内容是非常具有挑战性的。可以看出,目前对于这个任务仍然没有健壮的解决方案。在本节中,我们将回顾时间动作定位的相关技术。
众所周知,视频特征表示可以为视频动作提供有用的信息,并且很多实验已经被做了。在过去的二十年,众所周知特征提取的进展一般经历了两个重要的历史时期。一个是传统的动作检测阶段在2014年之前,另一个时期时深度学习阶段,在2014年之后。时间线框架如图2所示
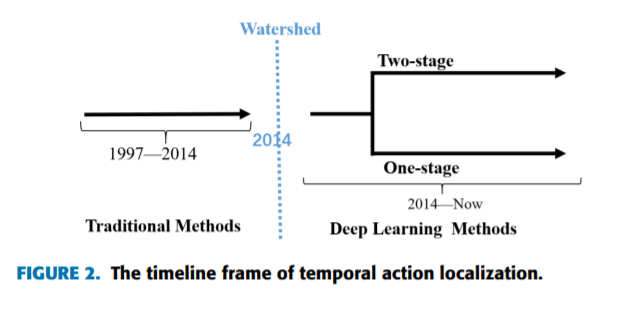
在深度学习阶段,它们主要被分为两种类型框架:“两阶段检测(‘two-stage detection)”和“一阶段检测(one-stage detection)”。特别,前面一种依赖“检测和分类”(proposal-then-classification)范式,这是一个主流方法,后一种同时检测和分类,所以我们称之为一级检测
A.传统的方法(TRADITIONAL METHODS)
由于动作识别是时间动作定位的一部分,所以大多数早期动作定位算法都依赖于手动制作的特点,这一点和动作识别相同。这里有几种方式去提取视频特征,包含静态图像特征和时间视觉特征。具体来说,静态图像特征是SIFT (ScaleInvariant Feature Transform,特性变换)和 HOG (Histogram of Oriented Gradients,倾斜的直方图)等待。HOG可以认为是SIFT的一种改进,然而时间视觉特征是静态图像信息和时间信息的结合。通过这些特征,可以得到视频的时间信息。
一般来说,我们能够将特征提取分为局部特征提取和全局特征提取。a)局部特征提取是指视频中的局部感兴趣点和感兴趣区域,包括统计数据,字段学习(dictionary learning),bagof-words (BoW),特征学习等等。和全局特征提取想比较,局部特征提取对于视频照明、投是、相机抖动和复杂背景更具有健壮性。b)全局特征提取指的是人类行为的整体特征,如人体的轮廓、骨架等,它包括全局密度和轨迹方法。为了解决在复炸场景中人类行为的问题,仅仅检测时空区域灰度变化是不够的。因此,研究人员已经提出了许多依赖于点轨迹的特征提取的方法。近似的过程如下:第一,这些方法先在视频的时间区域检测特征点,然后一帧一帧跟踪这些特征点,并将形成的特征点的轨迹连接起来,最后它们使用特征描述器(feature descriptors)来描述这个轨迹和它的时间域。许多特征提取的方法依赖特征点的轨迹传统方法是Dense Trajectories (DT),随后,考虑到摄像机的运动导致DT提取的特征和人类行为不相关关联,DT特征提取被更深的改进了,一种叫iDT的方法被提出。iDT的非常有价值的见解(valuable insight)仍然影响着以后的研究工作。值得注意的是深度学习和iDT的结合通常可以更进一步的提高性能。许多论文已经采纳以”我们的方法+iDT”的形式去实现最高水平SOTA(state-of-the-Art)
无论如何,传统特征提取方法的研究过程和思想非常有用,因为这些方法具有很强的可解释性。它们为设计深度学习方法来解决此类问题提供了启发和类比。
B.深度学习的方法(DEEP LEARNING METHODS)
随着使用手工特征提取的方法的表现变得稳定,时间动作定位以及达到了一定高度。随着卷积神经网络的重生,大量的研究也随之兴起。卷积神经网络可以学习见状的和高水准的特征表示。比如,一个2D-CNN对于一个大规模的视频分类是李菲菲的小组在年提出来的。虽然它的表现和依赖传统方法的特征提取不能相比,但是这个想法启发了后来的研究人员。后来,两种流派CNN((RGB frames and optical flow), 3D卷积神经网络和紧接着它们的变化成为了学习动作识别中的区别性特征受欢迎方法。随后,一个结合两种流派和C3D网络被命名为I3D(Inception 3D)被提出。而且它以及成为了一种通用的视频特征表示编码器(video feature representation encoder)。除了几种依赖神经网络的方法被介绍用来捕捉动态的动作识别,TSN通过稀疏采样的策略,也被设计来对整个视频信息进行平均聚集建模。根据图1,我们值得,深度学习分为两种类型:两阶段定位和一阶段定位。
1)两阶段定位方法
两阶段类型依赖定位-然后-分类( proposal-thenclassification)的范式.这个范式先提取时间定位,然后接着处理分类和回归操作。这方式是主流方法,所以大多数论文都是采用此方法。事实上,这个定位的生成是时间定位范式中的一个难点,这个和目标检测中定位的生成相类似(RNN中区域定位生成)。一个好的定位算法可以更好的提高这个模型的效果
时间动作定位生成器的任务是生成一定数量的时间定位对于一个未裁剪的长视频。一个时间动作定位是一个时间间隔包含动作片段(从起点边界到终点边界)。一般来说,平均召回率用来衡量算法的性能。数据库一般使用ActivityNet和THUMOS14,有几种方法提取定位的方法。
a:滑动窗口(SLIDING WINDOW,S-CNN [14], 2016)
在2016年,S-CNN第一个方法是固定一些大小滑动窗口去生成各种大小不同的视频片段,然后通过多级网络(SegmentCNN)处理这些片段。SCNN包括3个子网络都使用C3D网络。第一个是定位(proposal)网络,它用来确定当前路段是一个动作的概率,第二个是分类网络,用来给视频片段分类,第三个是定位(localization)网络,它的输出任然是一个类别的概率。并在训练过程中加入重叠相关的损失函数,使得网络能够更好地估计视频片段的类别喝重叠。原则上,当重叠度越高,效果越好。最后non-maximized suppression (NMS)被用于重复的片段和完成预测。
理论上,只有重叠足够高,这种方法是最全面的,但它有更多的冗余。
b:时间活动分组(TEMPORAL ACTIONNESS GROUPING,TAG [15], 2017)
以前的工作使用滑动窗口去提取建议的区域,但是这个方法不能处理不同视频动作长度。因为一般的是动作识别,卷积适用于密集视频帧,而且对于长动作视频滑动窗口消耗的资源太多。
Y. Xiong et al在2017年提出了一个新的框架用来准确的确定不同长度的动作视频的边界。这个框架包含两个部分:生成时间区域(generating temporal proposals)和分类待选(classifying proposed candidates)。前一部分生成一系列的建议区域,而后者确定它是否是一个动作并且预测它的类别。未来生成时间建议区域,TAG网络被提出。他们有三个主要步骤:a)提取片段(Extract snippets):每个片段包含一个视频的帧和视觉留信息,而且片段是在一个规律的间隔内获得的。b)动作:判断一个片段是否包含动作,为了做这件事,它使用TSN(Temporal Segment Network)学习二分类网络。c)分组:对于输出的片段序列和他们的概率,它将那些得分较高的连续片段进行分组。与此同时,设置一些阈值去删除分数较低的片段,以防止噪声干扰,并且通常设置多组阈值,以防止缺失建议区域。
这个方法对于边界更加灵活,但是它可能因为分类错误而错过一些建议区域
c:时间单位回归网络(TEMPORAL UNIT REGRESS NETWORK,TURN TAP [16], 2017)
在SCNN网络中,它使用滑动窗口去寻找建议区域。如果你想得到准确的结果,你需要增加窗口之间的额重叠,这回导致计算量大的问题。
为了减少计算量和增加时间定位准确度,在2017, Gao J.Y. et al在faster-RCNN映入边界回归方法的基础上,提出了转向学习的方法。这个方法将视频分割成固定大小的单元,列入16帧的单元,然后将每个单元放入C3D种提取水平特征。相邻单元形成一个clip,让么个单位形成一个锚单位,构成一个clip金字塔。然后在单元处进行时间坐标回归,这个网络包含两个输出,第一个输出是确定clip是否包含动作的分数;第二个输出是调整边界的时间坐标偏移量。
这个方法主要的贡献如下:1)一种利用坐标回归生成时间建议分段的新方法。2)快的速度(800fps)。3)一个新的评价指标AR-F被提出
d:边界敏感网络(BOUNDARY SENSITIVE NETWORK ,BSN [21], 2018)
众所周知,高质量的时间动作建议区域应该有一下几点特征:a)灵活的时间长度,b)精确的时间界限,c)可靠的信心得分。但是现有的方法不能同时兼顾这些方面,为了解决这些困难,T. Lin et al. [21]提出了BSN在2018年。
简略的说,BSN搜先定位时间动作片段的边界(开始节点和结束节点)。边界节点直接组合成一个时间建议区域。然后根据每个建议区域提案的动作置信度评分序列提取一个32维建议区域特征。最后,根据所提取的建议区域层次特征,对时间提案的置信度进行评估。
这方法主要的贡献如下:a)新颖的框架可以在同一时间满足上诉三点。b)BSN模块简单灵活,缺点是:a)对每个时间方案逐个进行特征提取和置信度评估,效率不够。b)语义信息不足。为了保证动作建议区域特征提取的效率,BSN设计的32维特征相对简单,但也限制了置信度评价模块获取更多的语义信息。c)该方法具有多阶段性。它没有联合优化网络的几个部分。
e:边界匹配网络(BOUNDARY-MATCHING NETWORK,BMN [72], 2019)
为了解决BSN的缺点,新的时间建议区域置信度评价机制喝边界匹配机制也由T. Lin在2019年提出。BMN能够生成一维边界概率喝二维BM置信度图。然后对所有可能的时间建议区域进行密集评估。
以上时间动作建议区域方法的性能比较如表1所示。

一阶段定位方法
另一种是同时处理建议区域和分类的一阶段框架。比如,在2017年T. Lin 提出SSAD和李菲菲提出了SS—TAD(端到端,单流时间动作检测)。他们都是基于单个检测器。由于时间动作定位和目标检测相似性,SSAD结合了YOLO和SSD两种目标检测模型的特点。SSAD的一般流程如下,使用提前训练的模型,得到特征序列,作为SSAD模型的输入。模型处理后输出检测结果。而SS-TAD将时间动作定位的语义子任务作为调整语义约束,提高了训练和测试性能。效果优于SSAD,SS-TAD提取特征使用C3D,与SSAD相同。而SS-TAD采用锚定机构和叠加GRU单元。最近,Fuchen Long介绍了GTAN(Gaussian Temporal Awareness Networks,高斯时间感知网络),该网络将时间结构与单阶段动作定位相结合。在GTAN,该算法引入高斯核函数,动态优化每个动作建议的时间尺度。
此外,有些方法基于顺序决策过程,也属于单阶段框架。例如,文献10是第一个提出在视频中学习动作检测的端到端的方法。在这篇文章中,它使用强化学习来训练一个基于rnn的代理。代理可以不断观察视频帧,并决定下一步看哪里,何时生成动作预测
3.基准数据集
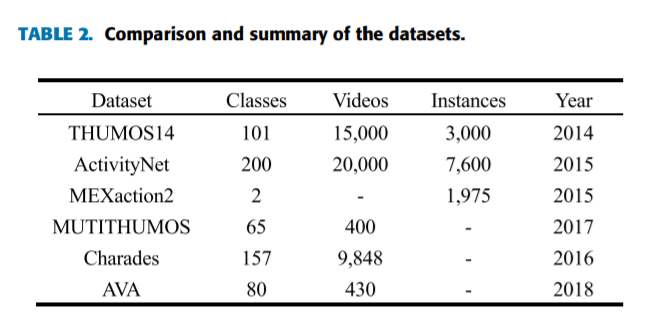
虽然没有一个时间动作定位的标准基准,但大多数研究人员使用THUMOS14[6]和ActivityNet [7]。此外,还有几个大型数据集用于时间动作检测。比如,MEXaction2、MutiTHUMOS、Charades和AVA等。下面这段主要介绍几种常用的数据集
A.THUMOS14
THUMOS14来自2014年的THUMOS Challenge。这个数据集包含两个任务:动作识别和时间动作检测。大多数论文都在这个数据集中进行评估。THUMOS数据集在其训练、验证和测试集中有101个动作类的视频级注释,而在20个类的验证和测试集中只有一小部分视频有时态注释。
一些全监督学习方法的细节如下:a)训练集:UCF101,101种动作类型,共计修剪了13320个视频剪辑。b)验证集:1010个未修剪的视频,其中200个贴有时间注释。(3007个动作片段,只有20个类可以用于时间动作检测任务)。c)测试集:1574个未修剪的视频,其中213个有时态动作注释。(3358个行为片段,只有20个类可以用于时间动作检测任务)
总之,这个数据集很有挑战性,因为有些视频比较长(长达26分钟),并且包含多个动作实例。动作的长度在一秒到几分钟之间变化很大。
B.ActivityNet
ActivityNet数据集是最近引入动作识别和动作定位基准的最大的非裁剪视频数据集。该数据集只提供YouTube视频链接,不能直接下载视频。所以我们需要使用YouTube下载工具自动下载。ActivityNet1.3包含10,024个训练视频,4,926个验证视频,5044个测试视频,200个活动类别,如“遛狗”、“跳远”和“给地板吸尘”。ActivityNet1.3 平均每个视频只包含1.5次出现,大多数视频只包含单个动作类别,平均36%的背景。
这个数据集包含在语义分类下涉及各种人类活动的大量自然视频。
C.MEXaction2
MEXaction2数据集包含两种类型的动作,即骑马和斗牛。这个数据集由三部分组成:YouTube视频,UCF101中的骑马视频和INA视频。其中UCF101中的YouTube视频片段和骑马视频是裁剪后的短视频片段,用于训练集,而INA视频是未裁剪的长视频,总长度为77小时。INA视频分为培训、验证和测试集。训练集、验证集和测试集中分别有1336、310和329个动作片段。
总之,MEXaction2 dataset的特点是未裁剪的视频非常长,注释片段只占整个视频的很小一部分。
D.MUTITHUMOS
MUTITHUMOS是一个密集的,多类,帧明智标签视频数据集,包括400个视频30小时,38,690个65个类的注释。平均每帧有1.5个标签,每段视频有10.5个动作类。这是THUMOS的增强版。目前,我们只在2017的论文“‘Learning Latent Super-Events to Detect Multiple Activities in Videos”中看到对该数据集的评价
E.CHARADES
Charades是未删减的视频,其中包含9,848个室内视频,(7985个训练数据,1863年测试数据),以及来自267个不同人的157个课程。每个视频大约30秒。每个视频都有多个注释,每个动作的开始时间和结束时间。
F.AVA
AVA是一个时空本地化的原子视觉动作数据集。它包含了430个15分钟长的电影片段,并注释了80个动作。有38.6万个标记片段,61.4万个标记包围框和8.1万个人员轨迹。总共有158万标记的行为,每个人经常有多个标记。
接下来,我们总结和比较这些数据集显示表2。
4.评价指标
A.基本概念
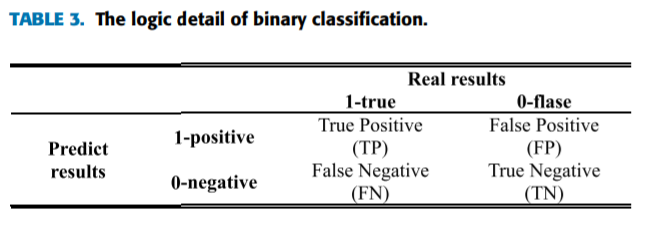
在二分类问题当中,TP代表True Positive,FP代表False Positive,TN代表True Negative,而FN代表False Negative。这四个参数被用来计算多种性能评价指标。给出了四个参数的逻辑细节在表3中。
其中,在实际的二进制分类中,positive-1标签指的是你比较关心的样本,比如一个动作或者一个异常事件。
1)ACCURACY
准确度是指正确分类样本的比例。它被用来评价分级机的性能。
2)RECALL
召回率是正确预测的范围。准确的说,找回是测试集中确定了多少真的positive样本。它的公式如下。
3)PRECISION
准确的说,准度是预测真实positive样本占预测结果的百分比。它的公式如下。
其中,n为真positive和假positive之和,n为系统识别的样本总数。
4)INTERSECTION-OVER-UNION (IoU)
IoU可以理解为模型预测的检测框与图像中目标检测的地面真实值的重叠。其实就是检测的准确性,计算公式为探测结果与地面真值的交点,并与两者的联合进行比较。
IoU用于检查预测结果与地面真实值之间的IoU是否大于预测阈值。我们通常把0.5作为阈值。如果IoU大于0.5,则该对象被识别为“检测成功”,否则被识别为“漏报”。在时间动作检测中,将IoU转化为时间的t-IoU,该t-IoU只有一维。
B. 评价指标
C.平均召回(AVERAGE RECALL,AR)
AR是时间动作建议区域生成的评价指标。因为时间动作建议区域生成不需要分类,它仅仅只需要去发现建议区域。因此,我们发现的时间动作建议区域是否完整,可以用来评估该方法的性能。所有我们经常使用AR来对此进行判断
D. 均值平均精度(MEAN AVERAGE PRECISION,mAP)
在时间动作定位任务中,mAP是最常用的评价指标。一般来说,我们在t-IoU = 0.5的情况下比较mAp。
简单地说, Precision (P)是给定视频中单个类的正确检测程度。例如,对于给定的单个视频,在公式中显示了类C的精度。
由于测试集中有很多视频,平均精度(AP)是类C中所有视频的平均精度。同时,由于测试集视频对应的类也很多,所以平均平均精度就是所有测试视频中所有类的平均精度。
总之,在某t-IoU下,P是某类C在视频中预测建议区域的准确性。AP是视频中所有类别的预测建议的平均精度。MAP是所有测试视频中所有类的预测建议的平均精度的平均值。在标准评价方案下,几乎所有的文献都报道了不同阈值的t-IoU下的mAP
5.最近的方法和发展
A.全监督时间动作定位(FULLY-SUPETVISED TEMPORAL ACTION LOCALIZATION,F-TAL)
1)全监督学习
==全监督学习是训练一种智能算法将输入数据映射到标签的过程,其中每个训练数据都有其对应的表示其ground truth的标签==。我们经常学习的分类和回归是监督式学习的代表。在时间动作定位任务中,全监督采用训练集的标签,该标签既包含视频级类别标签,又包含动作片段的时间标注信息(包括动作的开始时间和结束时间)。
2)目前具有代表性的方法
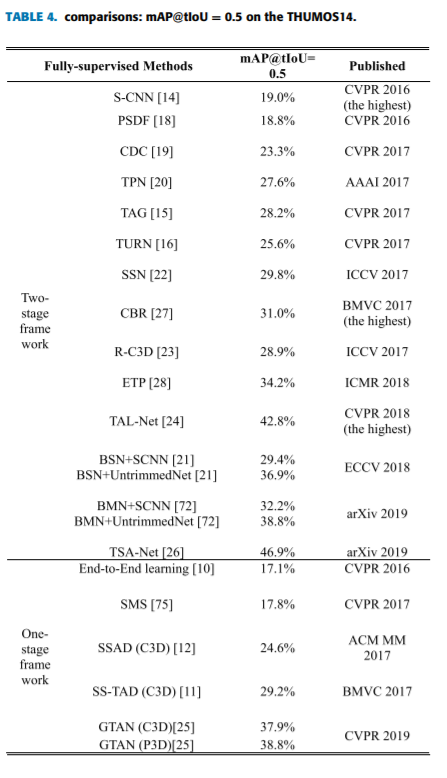
很多方法(如S-CNN[14]和PSDF[18])通过滑动窗口生成建议区域,并将提案分类为C + 1类,即C动作类和一个背景类。其中,S-CNN使用了多级CNN时间动作定位捕获鲁棒的视频特征表示。为了精确的边界,CDC [19] (Convolutional- de -Convolutional)网络和TPC-Net [20] ((Temporal Preservation Convolutional network)网络被提出用于帧级的动作预测。边界敏感网络(Boundary Sensitive Network, BSN[21])是最近提出的一种用于定位时间边界的网络,并进一步整合到动作建议区域中。次年,BSN的作者提出了一个新的时间建议区域置信度评价机制和边界匹配机制BMN [72]。BMN可以同时生成一维边界概率和二维BM的置信度图。为了保证建议区域的完整性,SSN[22]引入了结构化时间金字塔,利用解耦的分类器对行动进行分类和确定完整性。此外,一些基于区域的方法(如R-C3D[23]和talo - net[24])提出将二维目标检测方法推广到一维时间动作定位。最近,为了精确动作定位而提出了TSA-Net [26]和Gaussian temporal modeling [25]。下面是性能比较。为了简单和公平,我们在THUMOS14数据集和各种代表性方法的出版物上对mAP@tIoU = 0.5进行性能比较,如表4所示。
近年来,随着各种新型网络的引进,准确率已达到最新的46.9%[26]。当然,与图像中的目标检测还有一定的差距,这也是目前难以实现大规模商业化的原因。但我们可以相信,随着技术的不断进步,精度一定会实现突破。
B.弱监督时间动作定位(W-TAL)
由上节可知,目前的全监督学习技术在时间动作定位方面取得了很大的成功。因为许多现有的技术依赖于裁剪后的视频作为输入,例如:UCF101,他们有这些精确的时间注释。但在现实情况下,大多数视频都是未修剪并包含许多与目标动作无关的帧。因此,对时态标注的要求是非常困难的。具体原因总结如下:a)每个动作实例的帧级注释既昂贵又耗时。b)时间行为并没有明确的定义,这些时间行为的标注可能是因人而异的。
因此,弱监督学习方法越来越受欢迎。
1)弱监督学习
让我们看一看弱监督学习。这里有三种类型的弱监督学习。a)不完全弱监督学习。不完全监督,这只是训练数据的一小部分标记,而其他数据没有标记。例如,在图像分类中,我们可以很容易地从网上得到大量的图像,但由于人工成本昂贵,只有少数图像有注释。b)不精确弱监督学习。也就是说训练数据只有粗粒度的标签。我们还以图像分类为例。我们通常有图像级标签,但没有对象级标签。c)不准确弱监督学习。也就是说,给我们的标签并不总是真实的。例如,当图像注释器疲劳或者粗心大意的时候,或者一些图像很难分类的时候,就会出现这种情况。
由上可知,弱监督时间定位在训练过程中只有视频级标签,没有帧级时间标注,属于第二类弱监督,即不精确监督。
2)目前具有代表性的方法
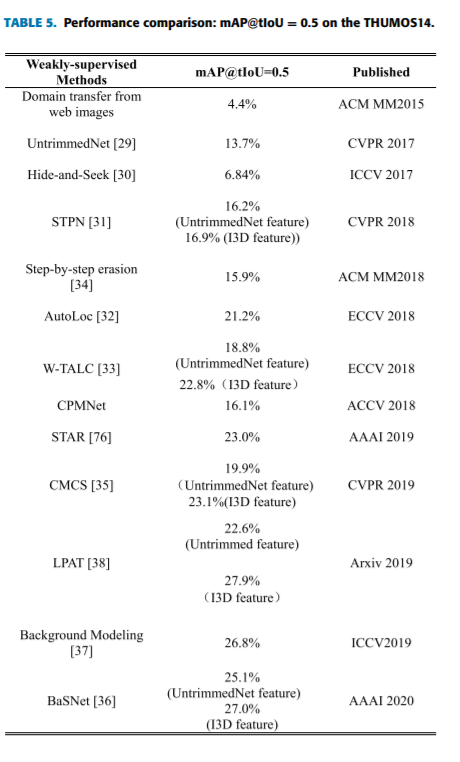
目前基于弱监督的定位方法很少,仅依赖于视频级的类标签来实现时间动作定位。受图像中弱监督目标检测的启发,研究人员对UntrimmedNet[29]和Hide-and-seek [30]进行了研究。UntrimmedNet是第一个提出动作识别和弱监督动作检测的公司。它是学习单标签动作分类和检测的一个端到端模型。STPN [31]是一个深度神经网络,依赖于分类。这个网络的总体结构如下:将视频分为N个片段,注意力模块可以识别关键片段的稀疏子集。然后我们就可以得到在分类标签预测过程中各个环节的重要性。因此,它能够通过自适应时间池化生成相应的类别标签和区间建议。AutoLoc [32]尝试根据CAS的阈值直接预测不同于以往弱监督时间动作检测的时间边界。==其主要思想是鼓励动作部分外的平均分低于动作类内的平均分==。W-TALC [33] 引入一种新的函数来进行K-max多实例学习,挖掘同一类局部实例之间的协同活动关系。为了解决分类器所关心的视频帧的碎片化和动作的完整性问题,Hide-and-seek[30]随机隐藏一些帧,迫使剩余注意力在每次训练中学习辨别度较低的视频帧。虽然,它不能保证在每次训练中都能发现新零件。结果表明,该方法对空间目标检测效果良好,但对时间动作定位效果不佳。Step-by-step erasion, one-by-one collection 对多个分类器进行擦除和训练,直接合并每个分类器的预测片段。性能好了一些,但是它花费更多的时间和计算。随后,CMCS[35]提出了一种具有多样性损失的多分支网络结构,用于动作完整性建模。与此同时,他们提出了一个方案,生成一个hard negative 视频来分离上下文。虽然本文的重点不是背景类,但它启发了接下来的三个作品,即BaSNet[36],background modeling[37]和LPAT [38]。在没有考虑背景类别的情况下,将背景帧误分类为动作类别,导致大量FPs。在BasNet中,为了构造背景类的负样本,在另一个网络中引入注意模块来抑制背景响应。另外两部作品从不同的角度考虑背景阶级,有效地抑制了背景的影响。最后,它们都提高了定位的准确性。
以下是在THUMOS14数据集上的性能比较,与全监督学习和各种代表性方法发表的标准相同,如表5所示
3)对W-TAL问题的见解
近年来,多用例学习(multiple instance learning, MIL)被应用于W-TAL学习中。MIL模型不是使用一组单独标记的实例来学习,而是接收一组标记的包,每个包包含许多实例。如果我们把视频中的动作实例看作一个包,把视频级别的注释看作标签,那么W-TAL可以被表述为一个多实例学习的过程。
时序类激活映射(Temporal class activation mapping,T-CAM)或类激活序列(r Class activation sequence ,CAS)是近年来出现的另一种W-TAL方法。CNN可视化显示,CNN的卷积层作为动作探测器执行,尽管对活动的位置没有监督。类激活序列说明,CNN尽管接受过视频层次标签的训练,但仍然能够具有本地化能力。此外,基于弱监督目标检测的其他研究,如交互式标注和生成对抗训练,也对W-TAL的研究有所启发。
综上所述,弱监督学习降低了劳动和时间成本,但也增加了时间检测的难度。但对于大多数动作类的大多数视频剪辑来说,效果似乎还不错。当然,仍有很大的改进空间
5.未来方向和发展趋势
时间动作定位的应用实际上会越来越广泛,未来的发展趋势可能集中但不限于以下几方面
a)精度和效率的改进。通过与二维卷积法和三维卷积法的比较,二维卷积法的精度更高,但效率较低。如何更好地发挥二者的优势是一个可能的研究方向
b)动作检测将从时间动作检测扩展到时空动作检测[39]。也就是说,我们应该从一维的时间间隔检测到二维的时空盒,这样可以更全面的检测动作
c)在线视频的动作检测。这是一个处理视频流的过程,需要在线检测动作的类别,但检测时间过后无法知道内容。在线的设置更符合需要实时检测或预警的监控视频的要求,如异常检测[41]。
d)时间动作定位的弱监督学习将会越来越受欢迎。在许多任务中,由于数据标注过程成本高昂,难以获得完整的监管信息。
e)视频是一种包含图像和音频的多模态数据。是否利用音频信息辅助时间动作定位是值得考虑的方向。正如Aytar等人使用图像辅助音频分析[45]。
6.结论
在本文中,我们对时间动作定位进行了全面的概述。我们从时间划分的角度分析了相关技术:传统方法和深度学习方法。接下来我们总结基准数据集和分析评估指标。然后回顾了时间动作定位从完全监督学习到弱监督学习方法的最新进展。总之,我们试图给出时间行为本土化的相关性和现状。同时,我们也希望对时间动作定位感兴趣的读者有所帮助。
时间动作定位是视频理解领域的一个研究热点,具有很大的复杂性和挑战性。但是,我们相信在不久的将来,深度学习技术的应用可以改善结果,任务也会变得更加容易。