Background Suppression Network for Weakly-supervised Temporal Action Localization
提出问题:
弱监督视频动作定位中,先前的方法聚合帧级别的类分数,以产生视频级别的预测并从视频级别的动作中学习。此方法无法完全模拟问题,因为背景帧被迫错误地分类为行动类别,无法准确预测视频级标签。
做了什么:
设计了背景抑制网络(BaSNet),该网络引入了背景的辅助类,并具有带有非对称度量训练策略的两分支权重共享体系结构。这使BaSNet可以抑制来自背景帧的激活,从而提高定位性能。广泛的实验证明了BaSNet的效率及其在最流行的基准THUMOS14和ActivityNet上优于最新方法的优越性
BaSNet:有两条分支Base branch and Suppression branch
怎么做的:
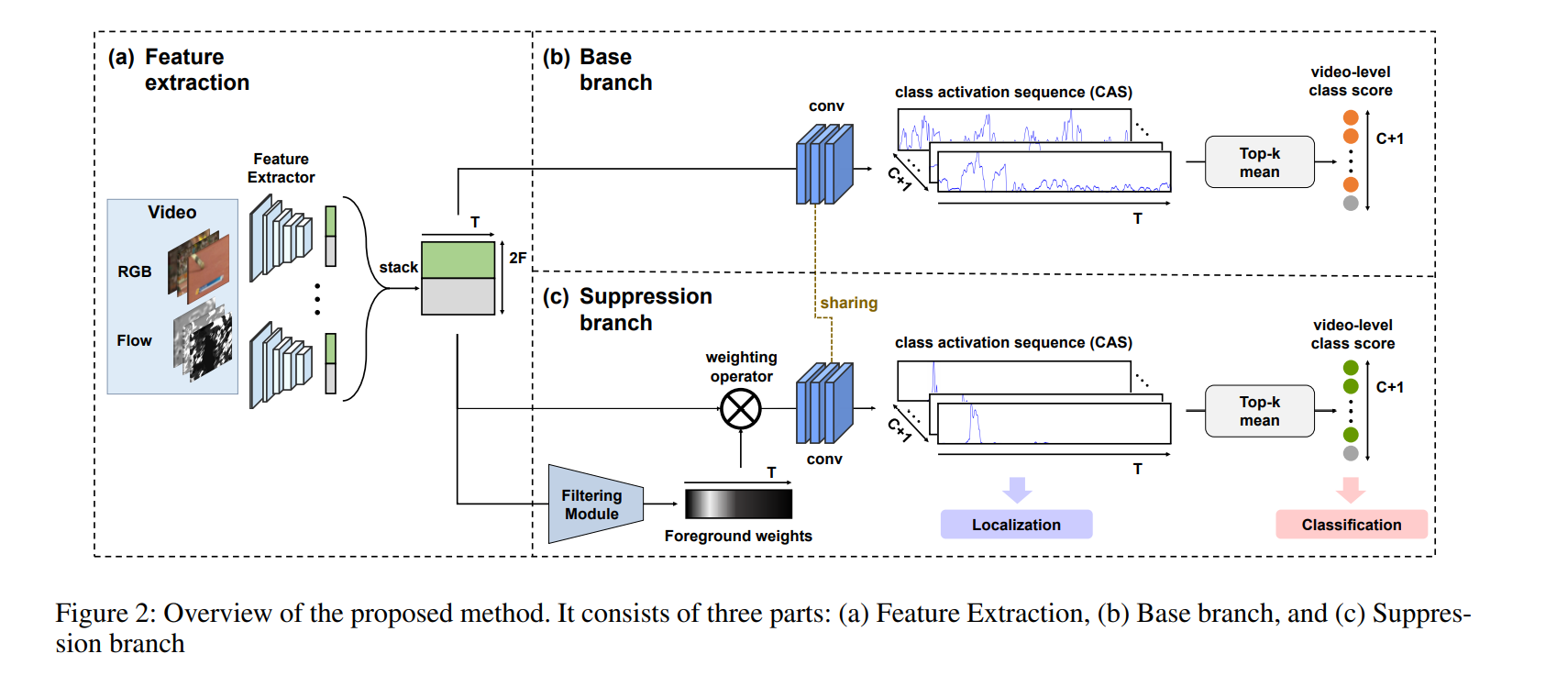
- Suppression分支包含一个过滤模块,该模块学习过滤出背景帧以最终抑制CAS中来自它们的激活
- 他们的培训目标是不同的。 Base分支的目的是将插入视频分类为其原始动作类和背景类的样本。另一方面,训练带有过滤模块的Suppression分支以最小化背景类得分,而背景类得分与原始动作类的目标相同。权重共享策略可以防止分支在给出相同输入时同时满足其两个目标。因此,过滤模块是解决背景的唯一关键,并且经过培训可以抑制来自背景框架的激活,从而同时实现两个目标。这减少了背景帧的干扰并提高了动作定位性能
特征提取:
由于存储器限制,我们首先将每个输入视频$vn$分成16帧不重叠的$L_n$段,即$v_n = {S{n,l} }^{Ln}{l = 1}$。为了应对视频长度的较大变化,我们从每个视频中采样了固定数量的T段。然后,我们将采样的RGB和flow分段输入到预训练的特征提取器中,以分别生成$F$维的特征向量$x{n,t}^{RGB}$和$x{n,t}^{flow}$。然后,将RGB和flow特征连接起来以构建完整的特征$x{n,t}$,然后将它们沿着时间维度堆叠以形成长度为T的特征图,即$Xn=[x{n,1},…,x_{n,T}]$
小结:这一步就是普通的特征提取,提取RGB和flow光流特征,然后将它们连接一下比较简单。
Base branch
为了预测线段级别的类别得分,我们通过将特征图馈送到时间一维卷积层中来生成CAS (类激活序列),其中每个线段都有其类别得分,反应了对应类别的概率。对于视频$v_n$,可以将其形式化如下:
其中$\phi$表示卷积层中的可训练参数,$A_n\in R^{(C+1)\times T}$。一个$C+1$尺寸是因为我们使用C动作类和一个辅助类作为背景。
接着使用top-k均值技术,可以如下得出视频vn的c类的视频级类评分:
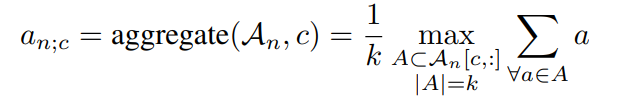
然后,通过沿类别维度应用softmax函数,将视频级别的类别得分用于预测每个类别的样本的概率:
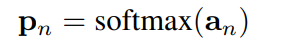
为了训练网络,我们为每个类别定义一个具有二进制交叉熵损失的损失函数$L_{base}$
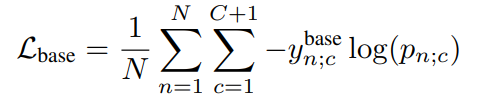
其中$y^{base}n=[y{n;1},…,y_{n;C},1]^T\in \mathbb R^{C+1}$,其中最后一个1是背景类,因为基础分支没有去除背景所以设置为1这和后面的抑制分支想对应。
小结:可以知道Base branch只是简单的进行训练,默认是有背景类的。
Suppression branch
与Base分支不同,Suppression分支在其前面包含一个过滤模块,该模块被针对背景类的相反的训练目标训练为抑制背景帧。过滤模块由两个时间一维卷积层和随后的S型函数组成。过滤模块的输出是前景权重$W_n∈R^T$,范围从0到1。来自过滤模块的前景权重在时间维度上与特征图相乘以过滤出背景帧。此步骤可以表示如下:
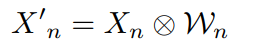
接着的话和前面Base 分支的训练类似,只是将$\acute{X}_n$ 代替$X_n$
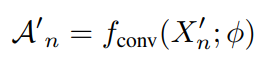
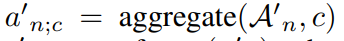
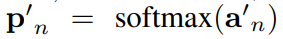
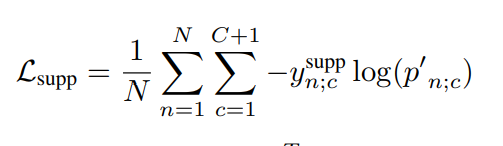
其中$y^{supp}n=[y{n;1},…,y_{n;C},0]^T\in \mathbb R^{C+1}$,其中最后一个1是背景类,因为基础分支没有去除背景所以设置为0,因为抑制分支经过了前面的过滤模块,默认是过滤掉背景。
小结:抑制分支设置背景类为0,目的就是训练过滤模块,他们俩共享了前面的一维权重,但是最终一个有背景一个没有背景,两个分支的区别就在于过滤模块,这也是所谓的非对称共享权重训练。
Joint training
我们联合训练base分支和Suppression 分支。我们需要优化的总体损失函数如下:
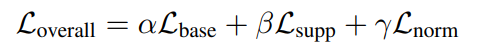
前两个在上面已经介绍了,而$L_{norm}$:
这个其实对训练的过滤模块权重进行$L_1$正则,目的是使得权重更加偏向0或者1,简单理解就是背景帧就是0进行抑制,动作帧就是1不受影响。术语就是更好的识别关键帧
小结:这个$L_{norm}$的设计还是比较巧妙,可能也是我接触比较少
Classification and Localization
在描述了我们的模型是如何配置和训练的之后,我们转向讨论它在测试时如何工作。由于我们使用过滤模块阻止来自背景框架的激活,因此使用Suppression分支的输出进行推理是合理的。对于分类,我们丢弃在概率低于阈值$\theta{class}$的类。然后,对于其余类别,我们使用阈值$\theta{act}$对CAS进行阈值选择候选片段。然后,每组连续的候选段将成为一个建议。我们根据最近的工作,使用内部和外部区域之间的对比来计算每个建议的置信度得分。
小结:这个分类和定位比较平常 ,不多介绍
结束语
这篇Background Suppression Network for Weakly-supervised Temporal Action Localization还真的在设计上就十分巧妙,两个分支一个训练有背景,一个训练却没有背景,两个分支的不同之处就只有过滤模块,所以说明了过滤模块的作用。最终的话使用过滤分支输出的概率和CAS来进行定位也是比较合理。