Learning Temporal Co-Attention Models for Unsupervised Video Action Localization
提出问题
未修剪视频中的时间动作定位(Temporal action localization,TAL) 最近获得了巨大的研究热情,但是TAL目前并没有无监督的的方法出现,所以本论文提出了第一种无监督的TAL方法。
做了什么
为了解决动作定位,两步进行 “聚类+定位”迭代过程。
聚类步骤为定位步骤提供了noisy的伪标记,而定位步骤提供了时间共关注模型,从而提高了聚类性能,这两个过程相辅相成。
在弱监督下 TAL可被视为我们ACL的直接扩展模型。
从技术上讲,我们的贡献有两个方面:
从视频级标签或伪标签中学习的时间共同注意模型,无论是针对特定类别还是不可知类别的 以反复强化的方式;
为ACL设计了新的loss,包括
action-background separation loss和cluster-based triplet loss。
最终的成绩:
针对20种动作THUMOS14和100种 行动ActivityNet-1.2。 在两个基准上,建议 ACL的模型具有强大的性能,甚至可以与最新的弱监督方法相比。 例如,以前最好的弱监督 在THUMOS14上的mAP@0.5下,模型达到了26.8%, 我们的新记录分别为30.1%(弱监督)和25.0% (无监督)。
怎么做
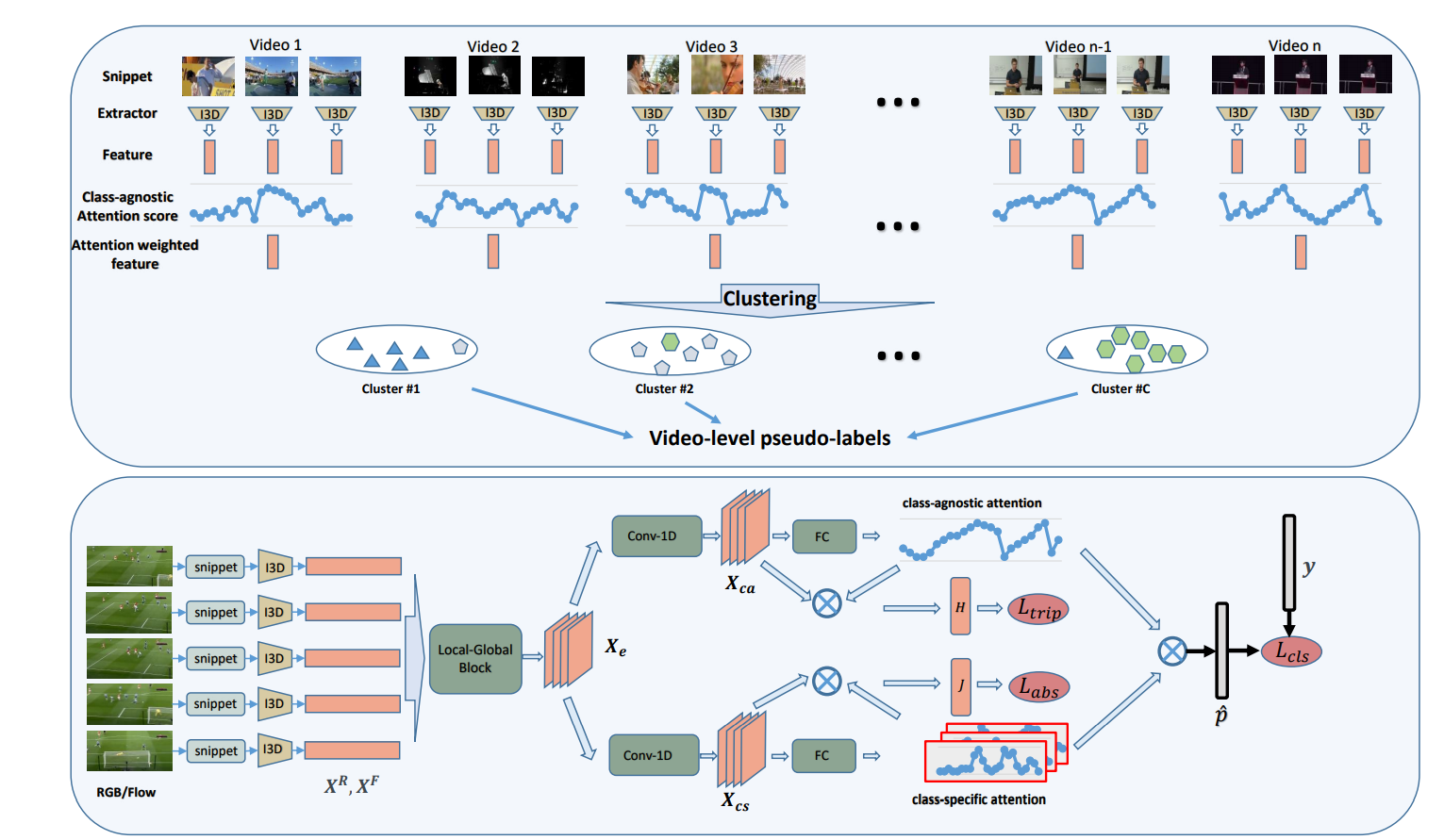
Video Feature Extraction
给定一个未修剪的视频,我 令$X^R,X^F\in \mathbb{R}^{T \times D}$分别代表片段式RGB和flow特征序列,其中$T$代表片段的数量,$D$代表特征尺寸。
Clustering
目前我们知道训练集的动作类别C的数量。为了获得每个视频的视频级伪标签,我们在训练集上利用频谱聚类算法来获得C个聚类,以便可以根据视频的分配给每个视频一个伪标签。
对于每个视频$v$,我们同样得到视频的RGB和flow特征$X^R,X^F\in \mathbb{R}^{T \times D}$,令$S^R{v,i},S^F{v,i} \in R ^{T_v×1}$为第i次迭代中的class-agnostic attention weights权重。因为这个是训练的时候才能得到所以最开始可以都设为1/T
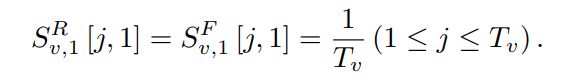
对于视频$v$在迭代i产生的RGB特征和光流特征就能得到
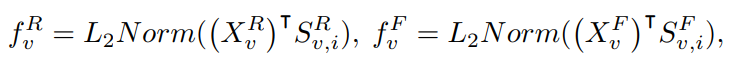
将每个视频$v$的RGB特征$f^R$和光流特征$f^F$ concatenate成最后的总特征$f_i$(这个目的是去除掉背景),这样就得到了每个视频$v$的特征,就可以构建图结构了。
对于图G = {V, E},其中V表示顶点的集合,即训练集视频,E表示边缘的集合。其中$vi,v_j$的权重$w{i,j}$由
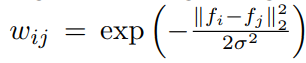
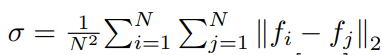
计算得来。基于构造的图,使用频谱聚类算法将未修剪的视频分组为C个簇,每个簇都定义了一个伪动作。然后,将这些视频级伪标签用于训练动作定位模型。对于弱监督扩展,每个视频均具有视频级别标签,因此跳过了聚类。
Local-Global Feature Aggregation Block
由于每个段的特征仅包含当前代码段的信息,因此缺少时间上下文信息。为了提高每个代码段特征的可分辨性,提出了局部全局特征聚合块(Local-Global Feature Aggregation Block,FAB)以提取局部和全局上下文信息
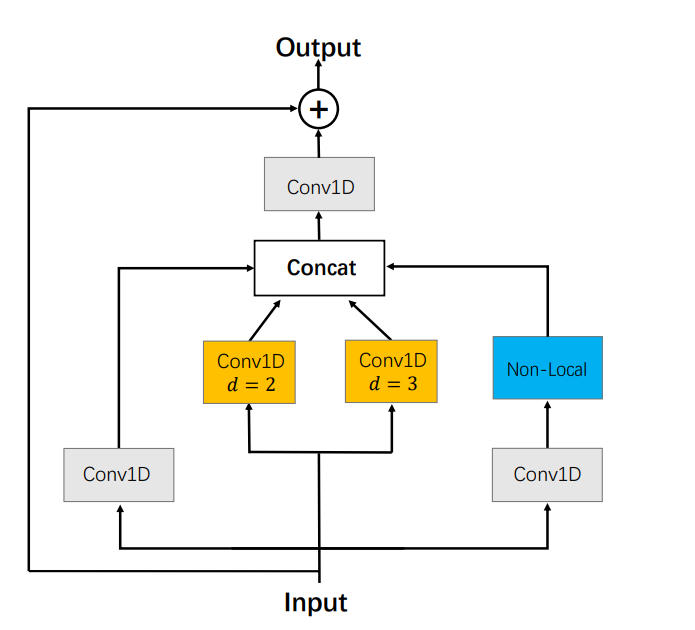
FAB主要是三个部分:
- a 1D temporal convolution branch
- a dilated temporal pyramid branch
- a global context branch
dilated temporal pyramid branch由2个并行的卷积组成,它们具有不同的扩张率,以聚集局部时间上下文。
global context branch使用non-local网络捕获所有帧之间的时间相关性。在全局上下文分支之前添加了内核大小为1的一维时间卷积以降低计算成本。
所有分支的输出通过一维时间卷积进行级联和融合。这步可以理解为将特征富含上了上下文信息,即视频的时序信息,经过了这个module后便得到了特征信息$X_e$
Class-Specific Temporal Attention Module
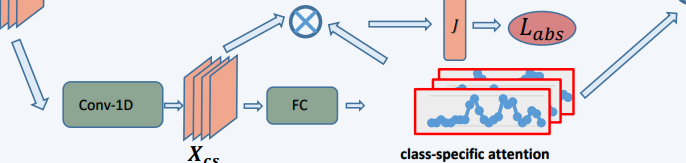
这个模块的功能主要是获得在不同时间出现的不同动作类别的概率。
以$X_{cs}$中间层作为输入,输出类特定分数$A \in R^{T \times C}$,其中T是分段数,C是分类总数,这里可以理解为分数A表示了每段是某一类动作的概率。最终还是加上了softmax来归一化
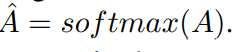
这个模块除了计算分数A之外,还会计算动作背景分离损失(action-background separation loss)。
对于一批训练视频,我们从随机训练集的$C$簇中,抽取出$Z$簇,再从$Z$簇中各自抽取出$K$个视频,定义$V_z$为属于某以簇的$K$个视频的集合
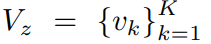
对于每个视频$v_k$,我们计算动作特征和背景特征
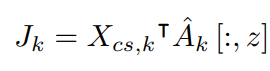
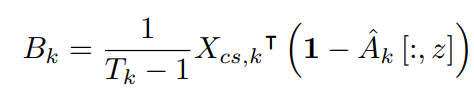
除此之外还要加上这三条限制:
假设我们有一对属于$V_z$的视频$v_m$和$v_n$。令d表示余弦距离函数,τ1和τ2分别表示两个cos余弦距离。
为了确保视频间动作的高度相似性,我们使用以下等式来强制执行此要求:
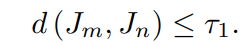
为了满足较高的视频内动作-背景清晰度,我们使用以下方程式:
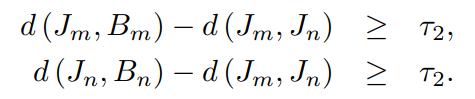
然后我们就可以得到损失函数
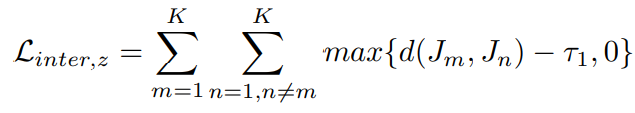
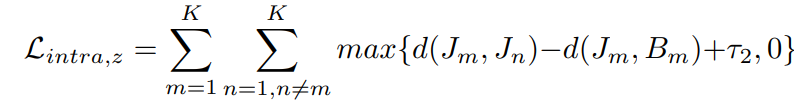
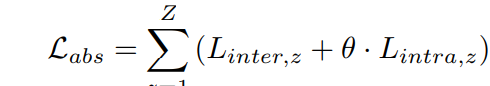
这个loss的作用主要是加强同簇中视频的动作相似性和动作背景的分离性
Class-Agnostic Temporal Attention Module
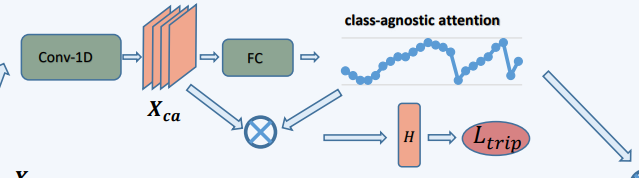
这个模块的功能是为了学习和动作类别无关的部分即背景部分出现的概率
以$X_{ca}$作为输入,输出类无关分数$S \in R^{T \times 1}$,这个分数和上面的$A$有相同的作用
除了计算$S$之外,这个模块也计算了cluster-based triplet loss,计算方式和上面有些类似
先计算class-agnostic video feature representation H
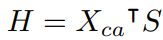
抽取出某一簇内的一个视频$v_a$,假设$v_n$是不在群集z中并且与$v_a$的距离最小的视频,$v_p$是群集z中的视频并且与$v_a$的距离最大,有这样的限制:
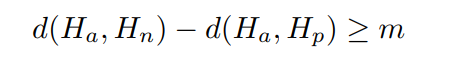
接着就可以计算cluster-based triplet loss
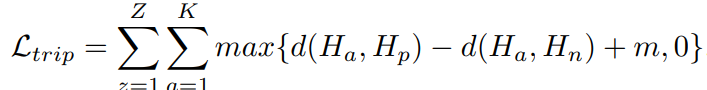
这个LOSS的意义很明确,为了将同一聚类的视频特征表示拉近,并将不同聚类的视频特征表示在特征空间中推得更远
最终loss计算
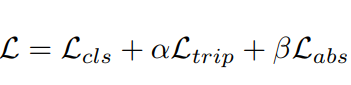
其中$L_{cls}$是经典的交叉熵损失
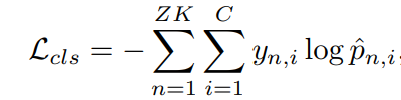
其中$y_n$表示视频$v_n$的标签,${p}^n$表示视频$v_n$的预测标签。
至于$p$的是计算方法则是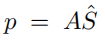
通过沿p上的类别维执行softmax,可以得到动作类$\hat {p}^n$上的概率分布
参考:https://blog.csdn.net/qq_43310834/article/details/108502214