CoLA Weakly-Supervised Temporal Action Localization with Snippet Contrastive Learning
提出问题:
弱监督时间动作定位(WSTAL)的目的是只通过视频级别的标签,对未裁剪的视频进行动作定位。目前存在的模型大都是遵循“localization by classification”的过程,定位对视频级别分类贡献最大的时间区域,一般来说,它们单独处理每个片段(或帧),因此忽略了有效的时间上下文关系
做了什么
- 提出利用视频片段对比学习来实现动作定位
- 提出了一个Snippet Contrast (SniCo) Loss来从特征空间中hard snippet的表示,它指导网络感知精确的时间边界,避免时间间隔中断。
- 由于没有办法访问帧级别的注释,引入了一种hard snippet挖掘算法,来定位潜在的hard snippet(这里的hard snippet可以理解为在背景和动作过渡区域的snippet,具有比较强的欺骗性)。
怎么做
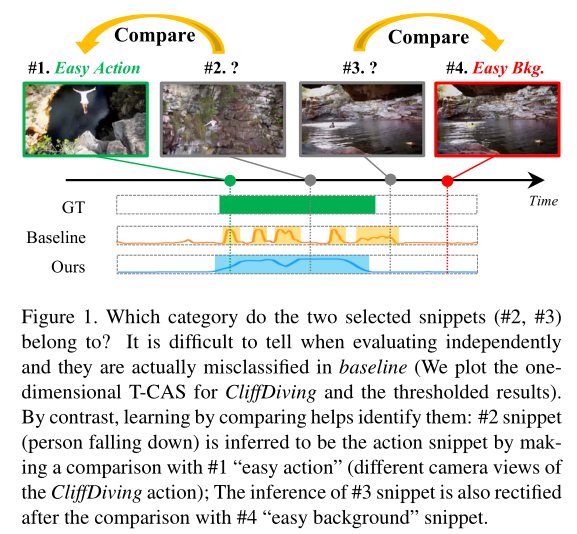
论文的动机可以从图中看出,由于缺乏帧级别的标签,上图中#2和#3这两个片段很难进行分类,如果只是使用baseline,我们会发现#2被识别为背景,而#3被识别为动作,这和GT是相违背。但是我们发现在这些片段中#1是很容易分类成动作(论文称这很容易识别的动作片段为easy action),而#4很容易分类背景(论文里面称为easy bkg),我们将#2和#1进行对比很容易发现#2是个动作,#3和#4对比很容易发现是背景,通过这种对比的思想就提出了这篇论文的模型。论文中将类型#2和#3的片段成为hard snippets,因为他们都是“cheating”的
论文的模型如下
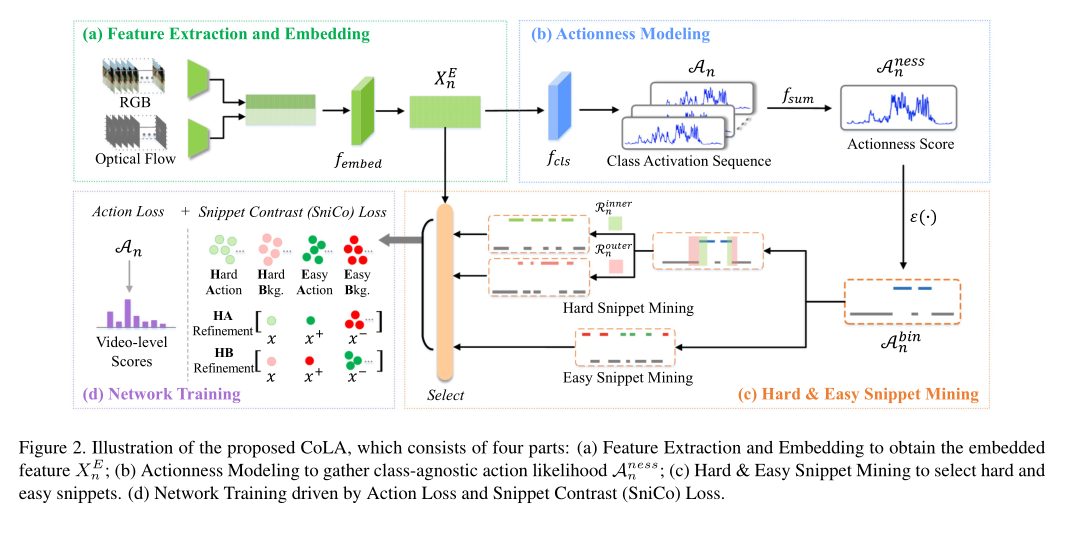
Feature Extraction and Embedding
给定$N$个未裁剪的视频$\lbrace{Vn}\rbrace^N{n=1}$和它们视频级别的标签 $\lbrace yn\rbrace^N{n=1}$ ,其中 $y_n\in \mathbb R^C $ ,$C$是动作类别的数量
对于每个视频$Vn$,我们把它分成多帧不重叠的$L_n$片段,其中$V_n=\lbrace S{n,l}\rbrace^{Ln}{l=1}$,由于视频长度的变化,利用采样,固定视频为数量$T$的片段$\lbrace S{n,t}\rbrace^T{t=1}$(采样的方法很常见,也是正常的方法)。
接着提取RGB特征$Xn^R=\lbrace x_t^R \rbrace^T{t=1}$和flow特征$Xn^O=\lbrace x_t^O \rbrace^T{t=1}$,其中$x^R_t \in \mathbb R^d$和$x^O_t \in \mathbb R^d$,$d$是每个片段的特性维度。
我们使用函数$f_{embed}$,将$X_n^R$和$X_n^O$连接起来,获取我们所提取的特征$X_n^E \in \mathbb R^{T \times 2d}$
$f_{embed}$通过时间卷积和ReLU激活函数实现。
Actionness Modeling
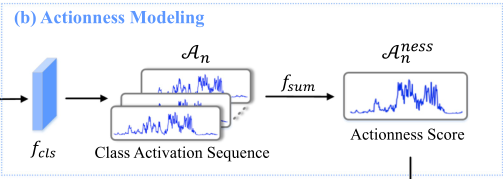
给定特征$Xn^E$ ,利用 $f{cls}$获得类激活序列即CAS(在论文当中叫T-CAS,其实概念是相同的)
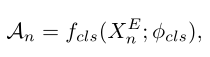
我们简单地沿着通道维度(fsum)加上Sigmoid函数对CAS进行求和,以获得一个类不可知的聚合,并使用它来表示动作
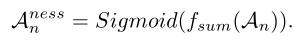
其中$A_n^{ness}\in\mathbb R^T$
Hard & Easy Snippet Mining
这一块是论文的创新点,主要挖掘论文当中Hard和Easy片段
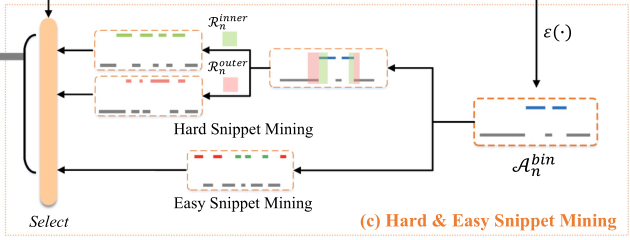
Hard Snippet Mining
hard Snippet 指那种边界相邻的片段,由于它们位于动作和背景之间的过渡区域,因此可靠性较差,从而导致检测模糊。所以hard snippet是可以进行挖掘,以得到更好的判决。在论文中构建了一种新的硬片段挖掘算法来挖掘边界区域的硬片段。
首先,我们对动作评分进行阈值,以生成一个二进制序列(1或0分别表示动作或背景位置):
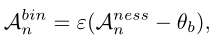
其中$\epsilon(\cdot )$是一个heaviside跃阶函数,其中$\theta_b$是阈值,如果$A_n^{ness}\geq\theta_b$,则$A_n^{bin}=1$,反之则为0
接着我们采取两种级联的扩张或者变窄操作(这个操作在语义分割动作有所使用),来扩大或缩小动作间隔的时间范围,将扩张和变窄程度不同的不同区域定义为硬背景(hard background)或者硬动作(hard action)区域。
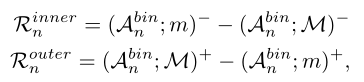
其中(·;∗)+和(·;∗)−分别表示mask∗下的二元扩张和变窄操作。这个些个操作类似卷积,作用是挖掘出hard的片段。
内部区域$R_n^{inner}$定义为mask较小m和mask较大的M变窄序列之间的不同片段的差值,如图3左边部分(绿色部分)所示。
同样,外部的$R_n^{outer}$计算为mask大掩码M和小掩码m之间的差值,如图3右侧部分(粉红色)所示。
经验上,我们考虑内部区域硬动作片段集,因为这些区域是$A_n^{bin}$= 1。同理外部区域被认为是硬背景代码片段集。

接着定义hard action snippets,$X_n^{HA}\in \mathbb R^{k^{hard}\times 2d}$,从$R_n^{inner}$中挑选出来
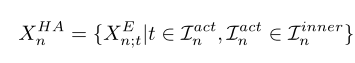
其中$I_n^{inner}$是$R_n^{inner}$内的代码片段的索引集,$I_n^{act}$是$I_n^{inner}$中大小为$k^{hard}$的子集,即$\lvert I_n^{act} \rvert=k^{hard}$。其中$k^{hard}$是一个超参,简单理解就是找了$k^{hard}$个hard action片段
同理可以得到 hard background snippets
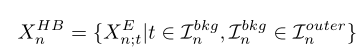
我们可以这样理解图3,对于左侧的图,我们先拿卷积核为3的神经元去移动,当3个位置都为1时(都为动作时),才把中心位置标为1,然后卷积核为6的神经元去移动,当6个位置都为1时才把中心位置标为1,显然卷积核为6的神经元比较严格看的更远,他减去卷积为3移动完的数据剩下的就是不是那么严格的位置,所以把这些位置作为hard snippet。
Easy Snippet Mining
为了形成对比对,我们仍然需要挖掘具有区别性的简单片段
我们假设动作度得分为top-k和bottom-k的视频片段恰好是easy action 片段($X_n^{EA}\in \mathbb R^{k^{easy}\times 2d}$)和easy background 片段 ($X_n^{EB}\in \mathbb R^{k^{easy}\times 2d}$),可以理解为选取了k个容易区分的片段
我们基于前面计算的动作评分$A_n^{ness}$进行简单的代码片段挖掘。
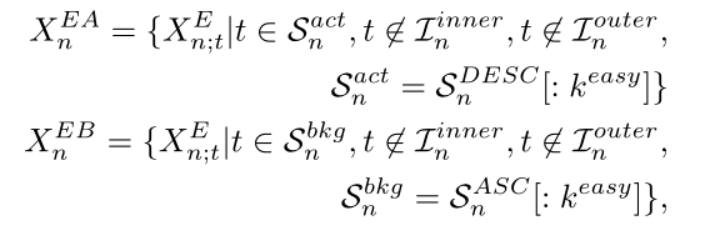
其中$S_n^{DESC}$和$S_n^{ASC}$分别为$A_n^{ness}$按照降序和升序排列的索引。基本理解和前面一样。
Network Training
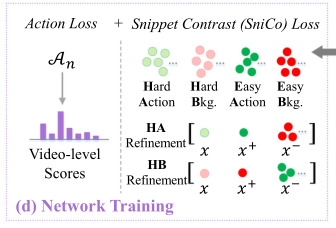
在挖掘hard和easy片段的基础上,我们的CoLA引入了额外的片段对比(SniCo)损失($L_s$),与基线模型相比取得了相当大的改进。全损可以表示为:
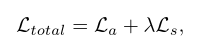
其中$L_a$和$L_s$分别表示动作损失和SniCo损失。$\lambda$是平衡因子。我们将对这两个术语作如下阐述。
Action Loss
Action Loss($L_a$)预测的视频类别与真实值之间的分类损失。为了获得视频级预测,我们聚合片段级别的类别分数(CAS),即$A_n$
然后采取top-k均值方法,对于每个类别$c$,我们取具有最大的类特定CAS值的$K^{easy}$项,并计算它们的平均值$a{n;c}$,即video $V_n$的class $c$的视频级类得分。在获得所有类的$a{n;c}$之后,我们在类维上应用Softmax函数得到视频级类的概率$p_n \in \mathbb R^C$
Action Loss($L_a$)使用交叉熵损失
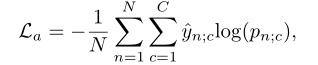
Snippet Contrast (SniCo) Loss
对比学习已经被用于图像或者补丁级别。对于本次论文,给定特征$X_n^E$,对比学习应用于代码片段级别。在论文中将这种命名为snippet Contrast (SniCo)Loss ($L_s$),目的是细化hard 片段,因为有hard action和hard background两个对比,所以我们分为“HA refinement” and “HB refinement”
查询$x\in \mathbb R^{1\times2d}$,positive $x^+ \in \mathbb R^{1\times 2d}$和$S$消极$x^-\in \mathbb R^{S\times 2d}$均从预挖掘片段中选取
对于“HA refinement”
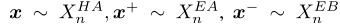
对于“HB refinement”
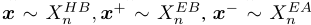
我们将它们投射到一个标准化的单位球体上,以防止空间坍塌或膨胀(没怎么看懂),不过这其实是一个简单对比学习。
建立了一个(S+ 1)分类问题,利用交叉熵损失来表示正例比负例被选择的概率
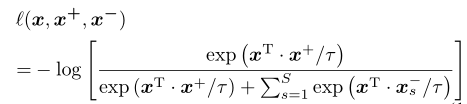
其中$\tau$是一个超参,而$x^T$为$x$的转置,建议SniCo损失如下:
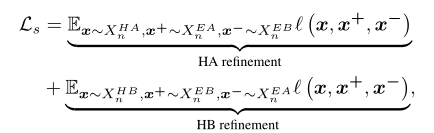
总结
本文思路不错,直接从以前WTAL中使用比较多的度量学习直接进入到对比学习,算是一种进步。
图像的 eroded和dilated操作可以看: