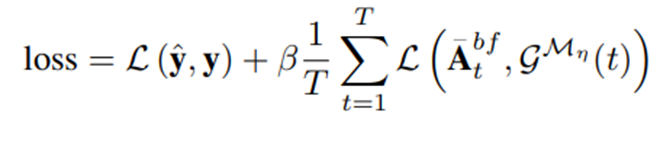RefineLoc Iterative Refinement for Weakly-Supervised Action Localization
提出问题
在目标检测领域,使用pseudo ground truth(类似于伪标签)进行细化大大减少了完全监督和弱监督对象检测之间的性能差距,因为时间动作定位很多内容是从目标检测当中引用过来的,那么是否能把使用pseudo ground truth这个方法引用到时间动作定位当中呢。
pseudo ground truth的概念是指来自弱监督模型的一组采样对象预测,在下一次细化迭代中将其假定为实际对象位置。
做了什么
提出RefineLoc模型,一种弱监督的时间定位方法,它通过利用pseudo ground truth实况来评估迭代细化策略
怎么做的
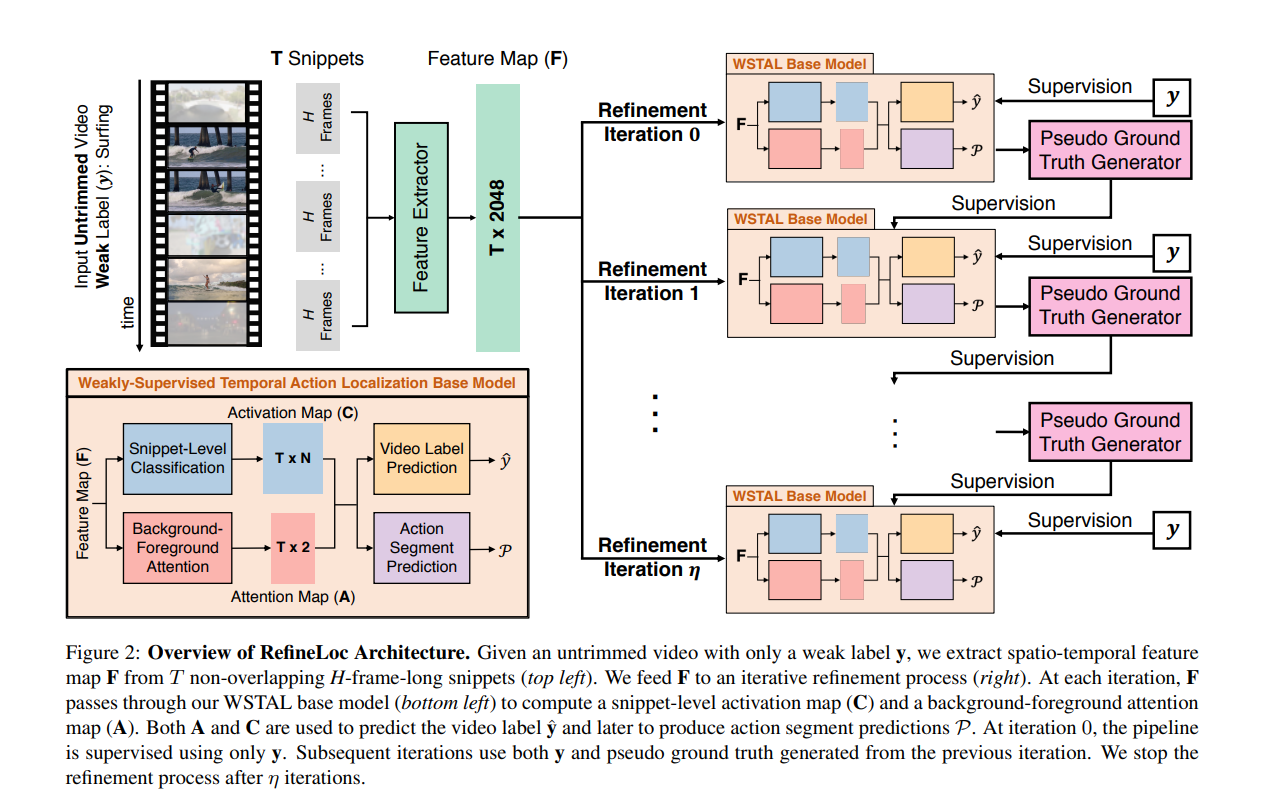
Snippet-Level Classification Module
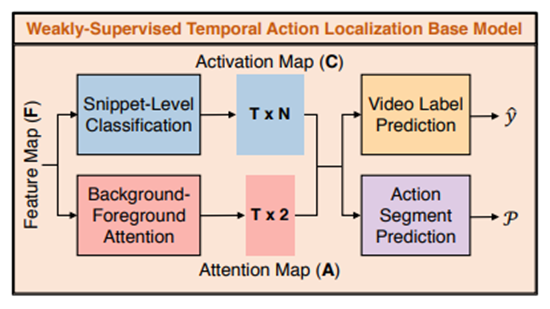
这个模块接受特征图F,然后产生T×N的类别激活图C(类激活序列的概念,在时间动作定位当中很常见,自行进行了解)
它由一个多层感知器 (MLP) 组成,其中 L 个全连接 (FC) 层与 ReLU 激活函数交错
Background-Foreground Attention Module
该模块的目标是学习每个片段的注意力权重,从而达到抑制背景的作用。
这个模块接受特征图F,然后产生T×2的类别激活图A(因为是背景,所以维度是$T\times 2$,和前面模块的的$T\times N$对比一下)
它由一个多层感知器 (MLP) 组成,其中 L 个全连接 (FC) 层与 ReLU 激活函数交错
别人的注意力模块仅受视频级别标签的监督,以改善视频分类,而本论文的注意力则由视频级标签和一组伪背景-前景标签,目的是提高动作片段的定位我们选择这样做是因为我们的方法直接对注意力值使用监督。因此,论文不是通过逻辑回归损失来学习注意力,而是将其作为二元分类问题来学习。我们将通过逻辑回归学习标量注意力与我们在补充材料中提出的二维注意力进行比较
Video Label Prediction Module
该模块结合 C 和 A 为视频标签生成 N 维概率向量 $\hat{y}$
具体来说,我们将 C 通过一个 softmax 层以获得$\bar{C}$,并将A通过两个 softmax 层。第一个softmax 层在background-foreground维度生成$\bar{A}^{bf}$,而第二个softmax 层是在$\bar{A}^{bf}$时间维度生成$\bar{A}^{time}$
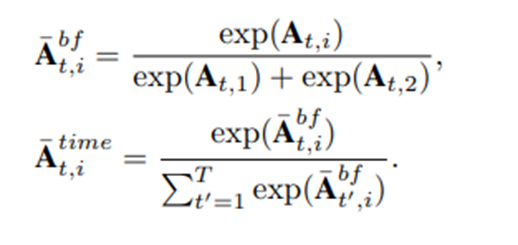
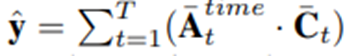
别人的注意力模块仅受视频级别标签的监督,以改善视频分类,而我们的注意力则由视频级标签和一组伪背景-前景标签,目的是提高动作片段的定位
我们选择这样做是因为我们的方法直接对注意力值使用监督。因此,我们不是通过逻辑回归损失来学习注意力,而是将其作为二元分类问题来学习。我们将通过逻辑回归学习标量注意力与我们在补充材料中提出的二维注意力进行比较i = 1 指的是背景,而 i = 2 指的是前景
Action Segment Prediction Module.
该模块后处理$\bar{A}^{bf}$和$\bar{C}$以产生一组动作片段预测P
首先,我们过滤掉背景注意力值大于阈值$\alpha_A$的片段。然后,我们只考虑$\hat{y}$中的 top-k 类。对于每个类别n,我们过滤掉片段分类分数低于$\alpha_c$
对于片段$(t_1,t_2)$
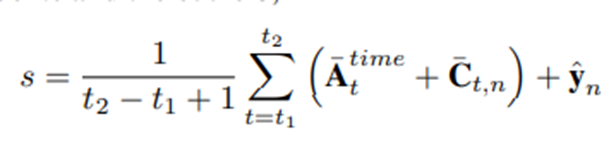
Iterative Refinement Process
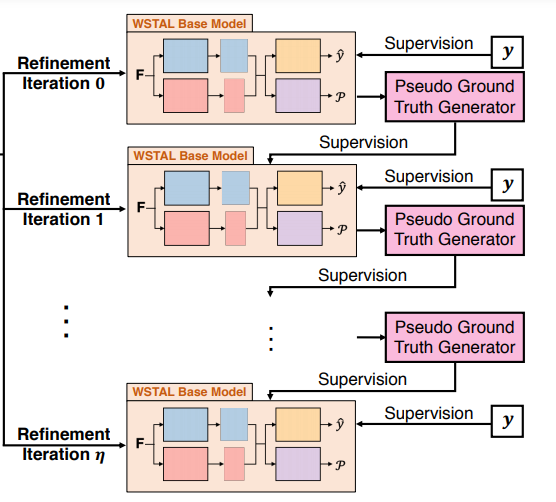
让$g^(Mη )$作为pseudo ground truth生成函数,使用来自$Mη$的信息(η迭代后训练的WSTAL基模型)将每个片段映射到伪背景-前景标签。在η+1迭代时,我们训练了一个新的WSTAL基模型Mη+1,用于计算视频级标签和片段级伪地面真标签的联合损失。具体地说,我们用下面的方法计算给定视频上的Mη+1的损失