End-to-End Object Detection with Transformers
提出问题
目标检测的目标是预测一个bbox的集合和各个bbox的标签。目前的检测器不是直接预测一个目标的集合,而是使用替代的回归和分类去处理大量的propoasls、anchors或者window centers。模型的效果会受到一系列问题的影响:后处理去消除大量重叠的预测、anchors的设计、怎么把target box与anchor关联起来。怎么能够简化这个流程,使得目标检测简单起来
做了什么
把目标检测看做是一种set prediction的问题,我们的方法也直接移除了一些人工设计的组件,例如NMS和anchor的生成。使用transformer来完成这一任务,在coco数据集上有着可以和faster-rcnn媲美的准确率与效率。
怎么做
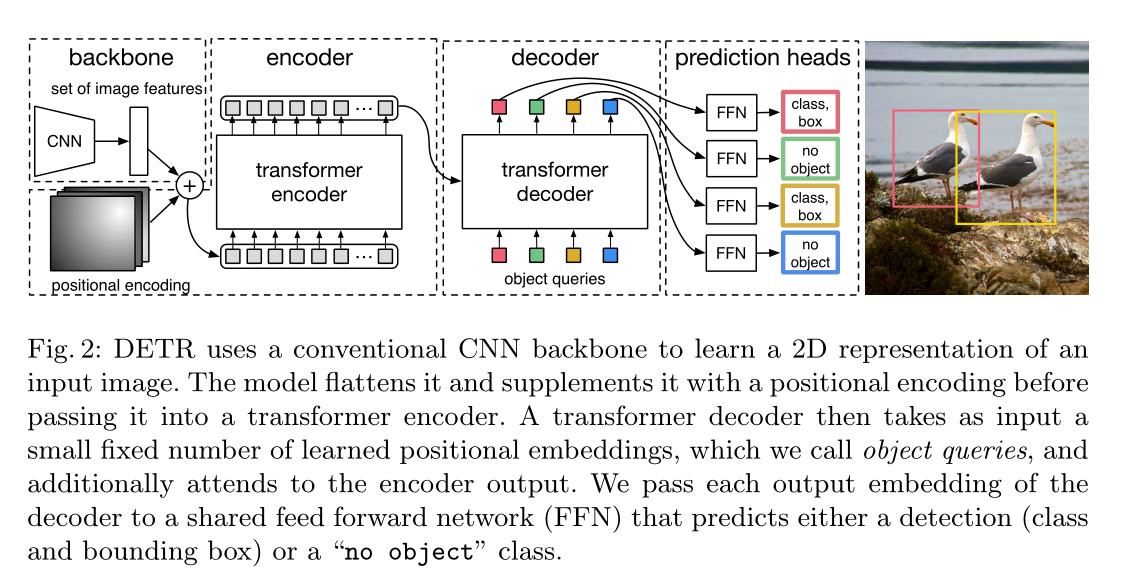
集合预测
集合预测是指网络直接输出最终的预测集合(这个集合不需要做任何后处理),这个集合包括预测框的位置和类别,所以能够直接得到预测的集合就可以达到目标检测的目的。
比如:在Detr中,transformer的后面的输出就是最终预测的结果,固定为100个预测结果也就说网络输出就是$ 100\times 4$和$100\times (C+1)$的两个tensor,分别对应框的预测和类别的预测,C表示总共的类别数,+1是背景类。
DETR 模型
目标检测中使用直接集合预测最关键的两个点是:
1)保证真实值与预测值之间唯一匹配的集合预测损失。
2)一个可以预测(一次性)目标集合和对他们关系建模的架构。
目标检测集合预测损失
DETR输出固定大小为N的预测,只需要执行一次解码器,N比常规图片中待检测目标大得多。训练中最难的地方就是根据真实值评价预测目标(类别、位置、大小)。我们的损失构造了一个最优的二分匹配而且接着优化目标向(bounding box)的损失。
用$y$表示真实值,$\widehat{y}=\lbrace \widehat{y}i\rbrace{i=1}^N$指示N个预测值。假设N远大于图像中的目标,我们可以认为y的大小也是N,用$\phi$填充空元素。目标就是找到这两个集合的二分匹配,中的一种排列$\sigma$有着最低的损失:
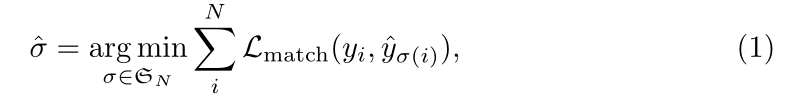
匹配损失同时考虑到类别与真实值与预测值之间的相似度,使用的方法是匈牙利算法
真实值每个元素都可以看作$y_i=(c_i,b_i)$,其中$c_i$是目标类别(可能是$\phi$),而$b_i \in [0,1]^4$可以理解为b是值域在[0,1]的四维向量,bbox的中心坐标与宽高。
对于$\sigma(i)$的预测,我们定义类别$ci$的概率为$\widehat{p}{\sigma(i)}(ci)$预测框为$\widehat{b}{\sigma(i)}$。我们定义$L{match}(y_i,\widehat{y}{\sigma(i)})$为
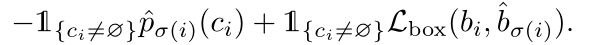
第二步就是计算损失函数,之前的步骤就是使用匈牙利算法计算所有的匹配。我们定义的loss与常见的检测模型很相似,就是负对数似然与box损失的线性组合。
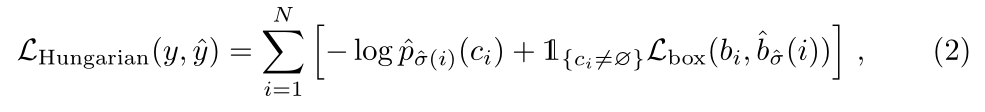
边界框损失
上面提到了$L{box}(b_i,\widehat{b}{\sigma(i)})$,$L{box}(b_i,\widehat{b}{\sigma(i)})$我们定义如下
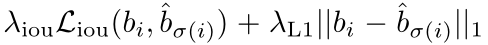
我们直接预测box在图像中的位置,直接使用L1loss的话,对小目标就不公平,因此我们使用了L1 loss 与IOU loss的组合,让loss对目标的大小不敏感。
骨架
开始输入原始图片大小为$x_{img} \in \mathbb R^{3\times H_0 \times W_0}$(三通道),使用CNN进行特征提取,最终得到特征图$f\in \mathbb R^{C\times H\times W}$,其中$C=2048$ 和$H,W=\frac{H_0}{32},\frac{W_0}{32}$
Transfomer encoder
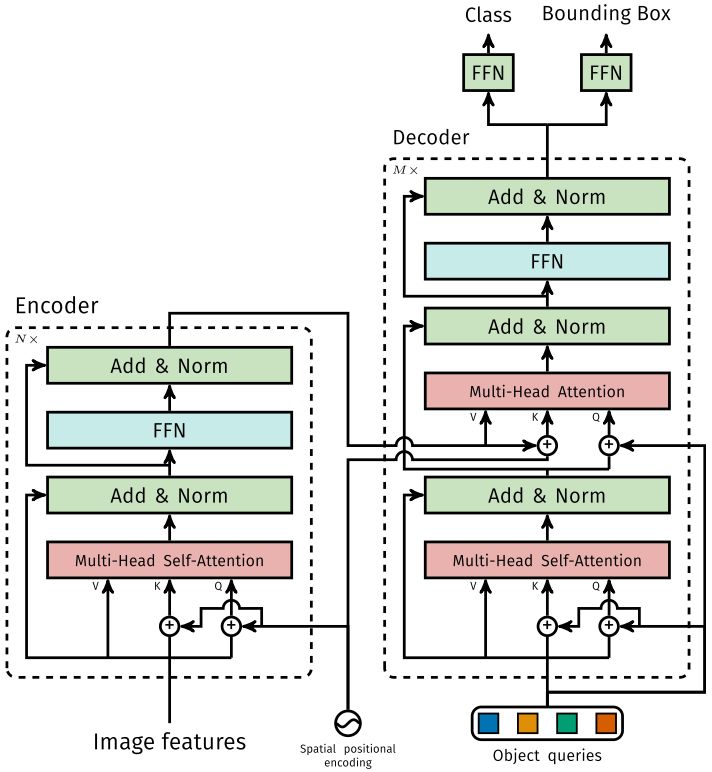
首先使用$1\times1$的卷积将原来的$C=2048$降维到$d$维,得到$z_0\in \mathbb R^{d\times H\times W}$的特征图,因为编码器需要一个序列作为输入因此我们将$z_0$压缩到一维,得到$d\times HW$的特征映射。每个encoder层由multi-head self-attention模块和FFN组成。由于transformer对排列顺序不敏感,所以我们加入了位置的编码,并添加到所有attention层的输入。
Transfomer decoder
与常规transformer的区别就是,本文可以并行的解码,而之前的transformer都是自回归的依次解码。由于decoder也是对排列顺序不敏感,这N个嵌入必须不一样,才能预测不同的结果。这些输入的嵌入是学到的位置编码,我们称之为object queries,类似于encoder,我们把它们加到每个decoder的输入。由于用了transformer,我们可以学习全局的信息。
Prediction feed-forward networks(FFNs)(预测前馈网络)
由三层的感知器计算,使用relu,隐层的size为d,线性的映射层。使用softmax输出类别概率。
总结
参考: