OadTR: Online Action Detection with Transformers
解决什么问题
该论文是解决的问题是在线动作检测。
在线动作检测的任务是在实时视频流当中,当事件发生时,检测事件开始的帧,以及事件的类型。

怎么做
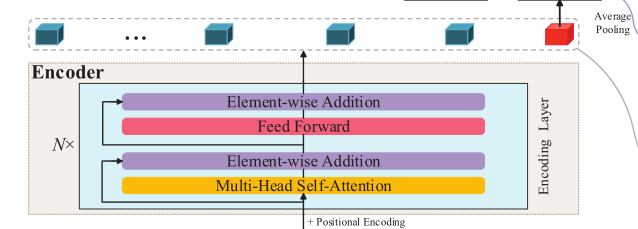
论文模型如下
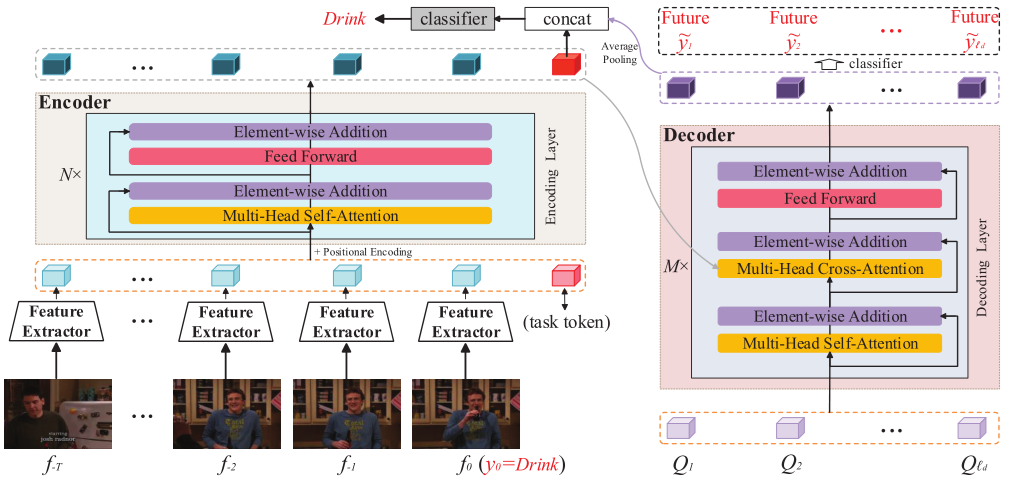
Encoder
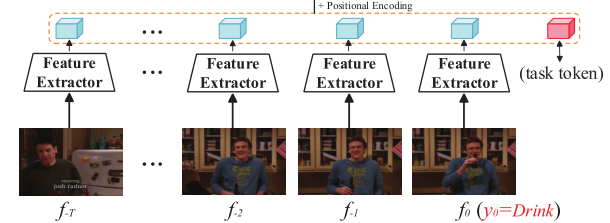
给定视频$V={ft}{t=-T}^0$,使用特征提取器通过压缩空间维度提取到一维特征序列,然后再使用线性投影层,得到$F={tokent }{t=-T}^0∈R^{ (T+1)×D}$
在encoder里面,将可学习的$token_class∈R^D$扩展到嵌入的特征序列
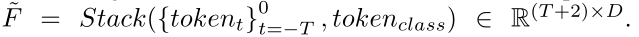
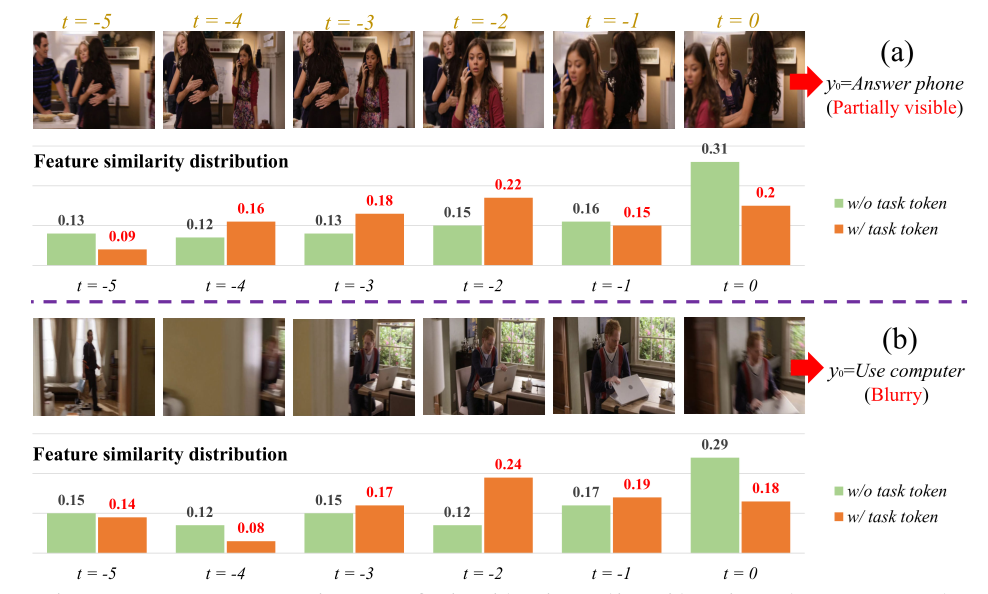
直观上,如果不存在token_class ,那么其他token获得的最终特征表示将不可避免地偏向于该指定的token作为一个整体,因此不能用来表示该学习任务(即图3中无任务token)。如下图,黄色部分就是有task token,绿色部分就是没有task token
由于encoder中没有帧顺序信息,所以需要另外嵌入位置编码。位置编码有两种形式:正弦输入和可训练嵌入。我们添加了位置编码$E_{pos}∈R^{(T+2)×D)}$
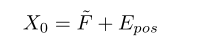
多头自注意(MSA)是变压器的核心部件。
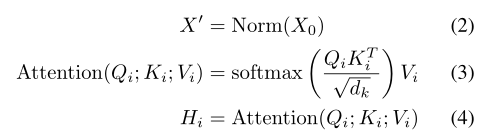
其中

随后,头的输出$H_1,H_2,…$被连接并馈入一个线性层
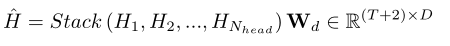
其中$W_d$是一个线性映射
接着,使用前馈网络(FFN)与GELU[19]激活。最后的公式可以表示为
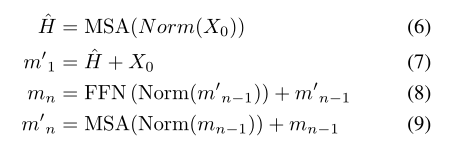
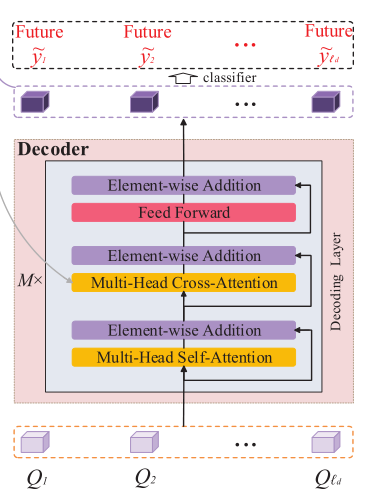
Decoder
OadTR的decoder利用对过去信息的观察来预测在不久的将来将要发生的动作,从而更好地学习更具甄别性的特征
预测查询
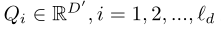
也是可学习的,其中$\acute{D}$是查询频道数量,最终得到输出
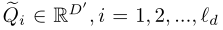
Training
对于当前帧块的分类任务,先将编码器中与任务相关的特征与解码器中池化的预测特征连接起来。然后生成的特征通过一个完整的连接层和一个softmax操作进行动作分类:
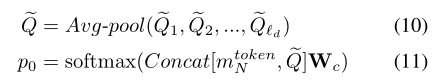
其中$W_c$表示用于分类的全连接层参数,$p_0∈R^{c+1}$。

除了估计当前动作外,OadTR还为下一步time步骤输出预测功能。由于离线训练时可以获得未来的信息,为了保证学习到好的特征表达式,我们还对未来预测特征进行了有监督的训练:
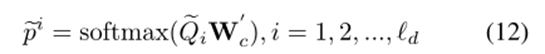
因此,最后的训练损失为:
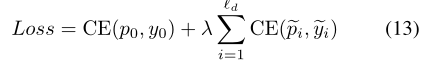
其中CE是交叉熵损失,下一步的实际行动类别是什么$\tilde{y_i}$