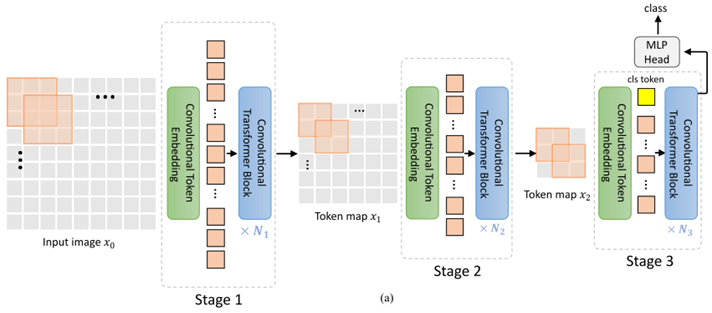
CvT:Introducing Convolutions to Vision Transformers
论文简介
CvT是发表在ICCV上的一篇文章,主要团队是来自麦吉尔大学, 微软云+AI。论文的主要工作是将卷积CNN模型引入Transformer模型中来产生两种设计的最佳效果,从而提高了视觉Transformer(ViT)的性能和效率
下面图展示的是团队成员:

思路和研究方法
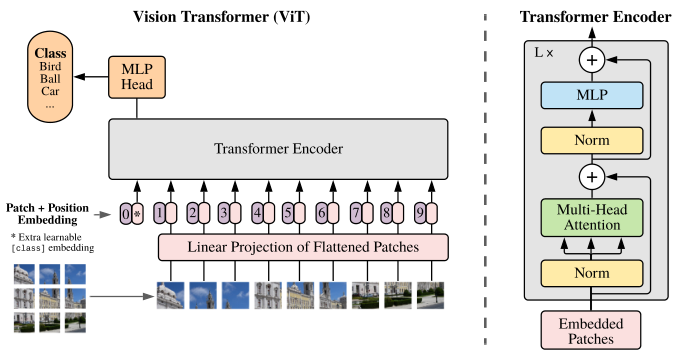
ViT模型
ViT模型通过将图片进行分块和降维,然后再送入到transformer中,实现了对图像进行分类。
缺点:ViT在小样本上,性能低于类似规模的CNN网络
Convolutional vision Transformer
本文提出了卷积视觉Transformer(CvT),设计了两个操作:Convolutional Token Embedding和Convolutional Projection,使得整个网络结构同时具备了卷积和Transformer的特点,去除了位置编码embedding,简化了网络设计。
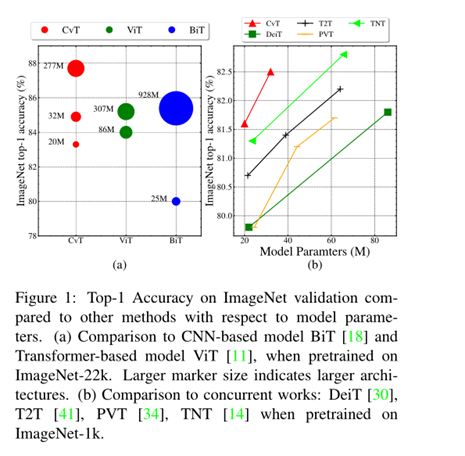
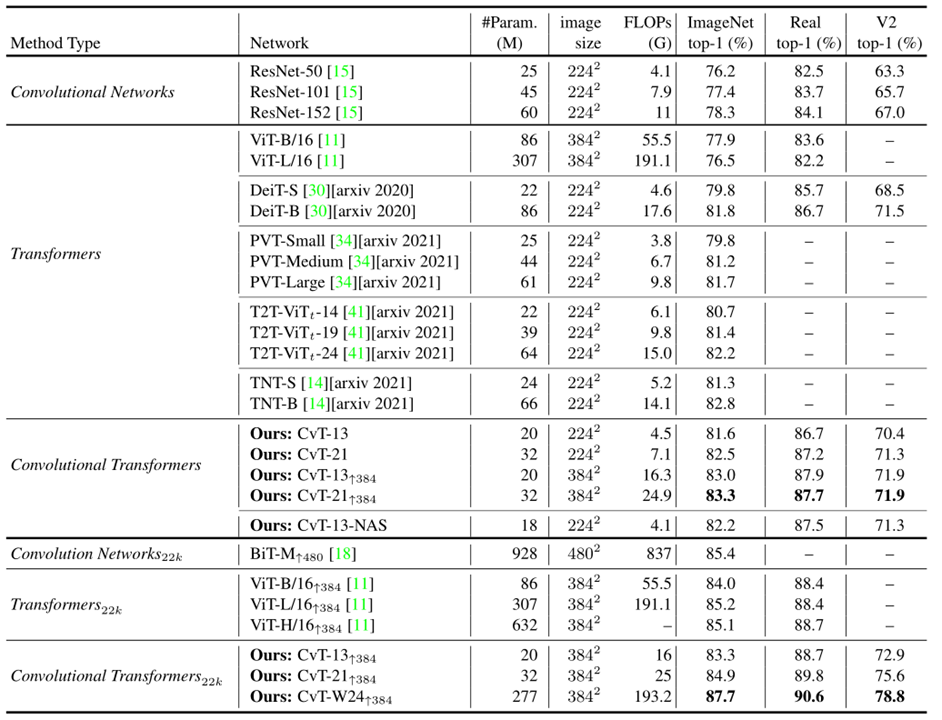
论文比较了一下CvT、ViT、BiT的参数,相同参数量下CvT模型准确度最高,如下图展示
本文的网络模型如下
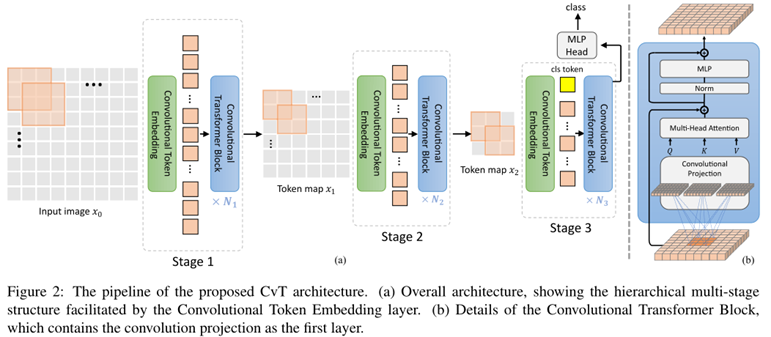
Convolutional Token Embedding
给定一个2D的image或者一个来自上一层的2D-reshaped输出$xi\in \mathbb R^{H{i-1}\times W{i_1}\times C{i-1}}$作为输入,学习一个函数$f(*)$,把输入$x{i-1}$映射到一个新的token$f(x{i-1}\in \mathbb R^{H_i\times W_i \times C_i})$,它的高和宽如下(其中卷积核大大小为$s\times s$,步长为$s-o$,padding为$p$)
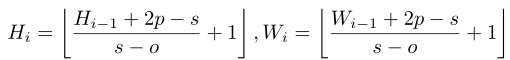
之后得到的$f(x_{i-1} )$会被flatten到$H_i W_i×C_i$ ,并进行Layer Normalization操作,得到的结果会进入下面的的第i个stage的Transformer Block的操作。
Convolutional Token Embedding允许我们通过使用不同的卷积参数,调整token feature dimension 和每一阶段的token数量。以该方式,我们渐渐减少token sequence length,同时增加token feature dimension。这使得token能够以增加更大的空间,去表征增加的复杂视觉模式。
Convolutional Projection for Attention
Convolutional Projection 层主要目标是实现额外的局部上下文建模,和提供高效的K,V矩阵采样方式。
从根本上来说,本文提出的带有Convolutional Projection 的Transformer block是原始Transformer block的一般化表示。因为先前的工作都是尝试在Transformer block 上添加额外的卷积模块,这增加了额外的计算代价。
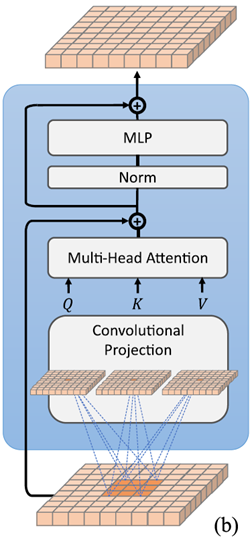
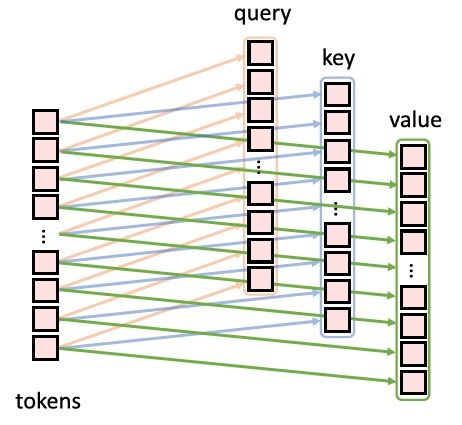
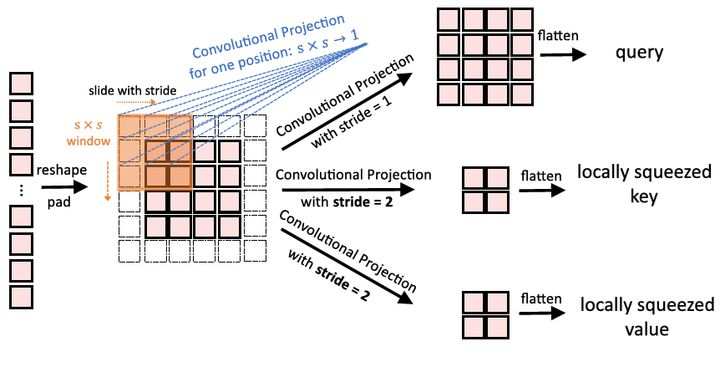
简单理解就是把普通Transformer的Block中的Linear Projection操作换成了Convolutional Projection操作,我们提出用深度可分卷积代替多头自注意(MHSA)的位置线性投影,形成卷积投影层。如下图所示为ViT中使用的Linear projection操作,采用的是线性的映射
如下图所示为CvT中使用的Convolutional Projection操作,采用的是卷积变换。
具体来讲,token首先reshape成2D的token map,再分别通过3个Depthwise-separable Convolution(kernel=s×s)变成query,key和value值。最后再把这些query,key和value值通过flatten操作得到真正的query,key和value值。
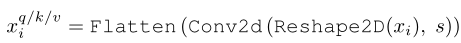
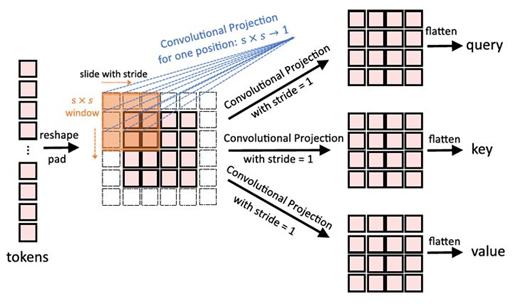
其中的Conv2d是个Depthwise-separable Convolution的复合操作
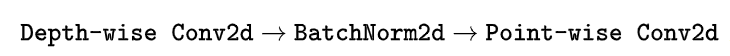
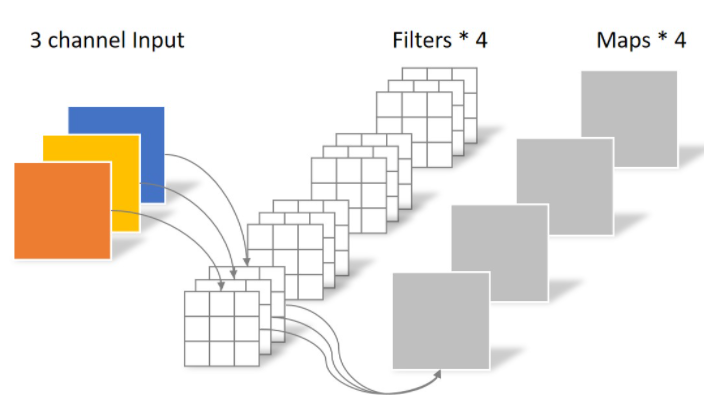
Depthwise Separable Convolution
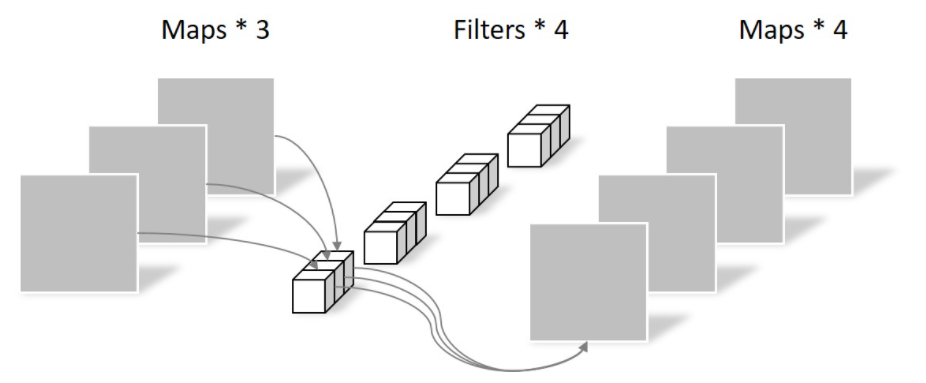
常规卷积运算:假设输入层为一个大小为64×64像素、三通道彩色图片。经过一个包含4个Filter的卷积层,最终输出4个Feature Map,且尺寸与输入层相同。整个过程可以用下图来概括。
Depthwise Convolution:一个大小为64×64像素、三通道彩色图片首先经过第一次卷积运算,不同之处在于此次的卷积完全是在二维平面内进行,且Filter的数量与上一层的Depth相同。
缺点:运算对输入层的每个channel独立进行卷积运算后就结束,没有有效的利用不同map在相同空间位置上的信息。
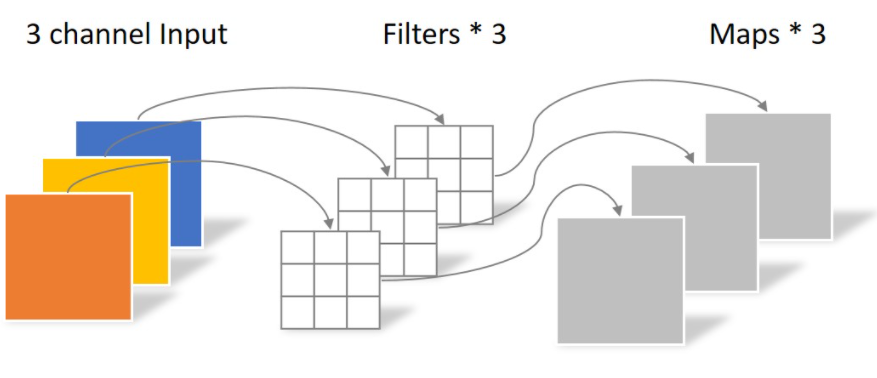
Pointwise Convolution:Pointwise Convolution的运算与常规卷积运算非常相似,不同之处在于卷积核的尺寸为 1×1×M,M为上一层的depth。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个Filter就有几个Feature map。
参数对比:
常规卷积的参数个数为:
Separable Convolution的参数由两部分相加得到:
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
Efficiency Considerations
对于常规的Convolution所需的参数量和计算量分别是 $s^2 C^2$和$o(s^2 C^2 T)$,
如果是Depthwise-separable Convolution所需的参数量和计算量分别是$s^2 C$和$o(s^2 CT)$
其中C是token的channel dimension,T是token的数量。
除此之外,为了使得模型进一步简化,作者又提出了如图所示的Squeezed convolutional projection操作。
作者在计算query时,采用的Depthwise-separable Convolution的stride值为1。在计算key和value时,采用的Depthwise-separable Convolution的stride值为2。如下图所示。按照这种方式,token的数量对于key和value来说可以减少4倍,性能只有很少的下降。
实验结果
数据集:ImageNet-1k (1.3M images),ImageNet (14M images,22k类),CIFAR-10/100,Oxford-IIIT-Pet,Oxford-IIIT-Flower。

CvT模型可以以较低的参数量和计算量达到更好的性能,比如21层的CvT在ImageNet上可以达到82.5%的高性能,比DeiT-B的性能还要好,而参数量和计算量都有大幅地下降。
CvT系列最大的模型:CvT-W24可以在ImageNet上达到87.7%的性能,不需要JFT-300预训练,超过了ViT-L模型。
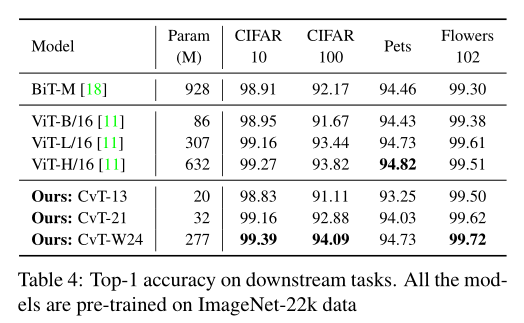
迁移学习性能
CvT在小数据集上的结果如图所示。
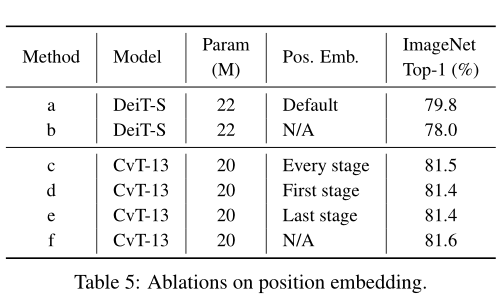
对比实验1:位置编码的影响
作者在CvT中没有使用位置编码,为了探究这么做到底会不会影响性能,作者设计了以下6个实验,发现DeiT在不使用位置编码时会掉点,但是CvT不使用位置编码则不会影响性能。根本原因还是CvT中的卷积操作自带了暗位置信息。
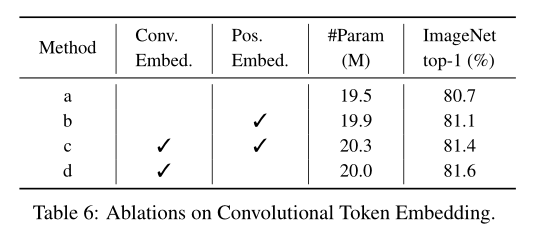
对比实验2:Convolutional Token Embedding的影响
为了说明Convolutional Token Embedding的作用,作者把它替换成了Patch embedding并做了如下4组实验。结果表明,当使用Convolutional Token Embedding并不使用位置编码时效果最佳,当使用Patch embedding并同时使用位置编码时效果次之。
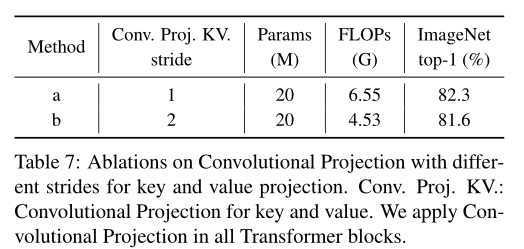
对比实验3:Convolutional Projection对比实验
作者首先对比了Convolutional Projection的stride的影响,当把stride=1换成stride=2之后,计算量会有下降,但是精度也有相应的下降。
作者对比了把 Convolutional Projection 替换成传统的Position-wise 的 Linear Projection之后的性能变化。结果发现在3个stage中都使用 Convolutional Projection 时的性能是最优的,证明 Convolutional Projection 是一种很有效的建模策略。

总结
首先embedding的方式变成了卷积操作,在每个Multi-head self-attention之前都进行Convolutional Token Embedding。
其次在 Self-attention的Projection操作不再使用传统的Linear Projection,而是使用Convolutional Projection。
最后取消位置编码,因为卷积操作包含了暗位置信息。
参考: