Weakly-supervised Temporal Action Localization by Uncertainty Modeling
提出问题
现有的Weakly-supervised Temporal Action Localization处理背景的方法存在很多问题,要不将静态帧合并合成伪背景视频,但忽略了动态背景帧,要不将背景框架划分为一个单独的类别。然而,强制所有的背景帧属于一个特定的类(背景类别其实也是不同的,因为它们不共享任何共同的语义)。

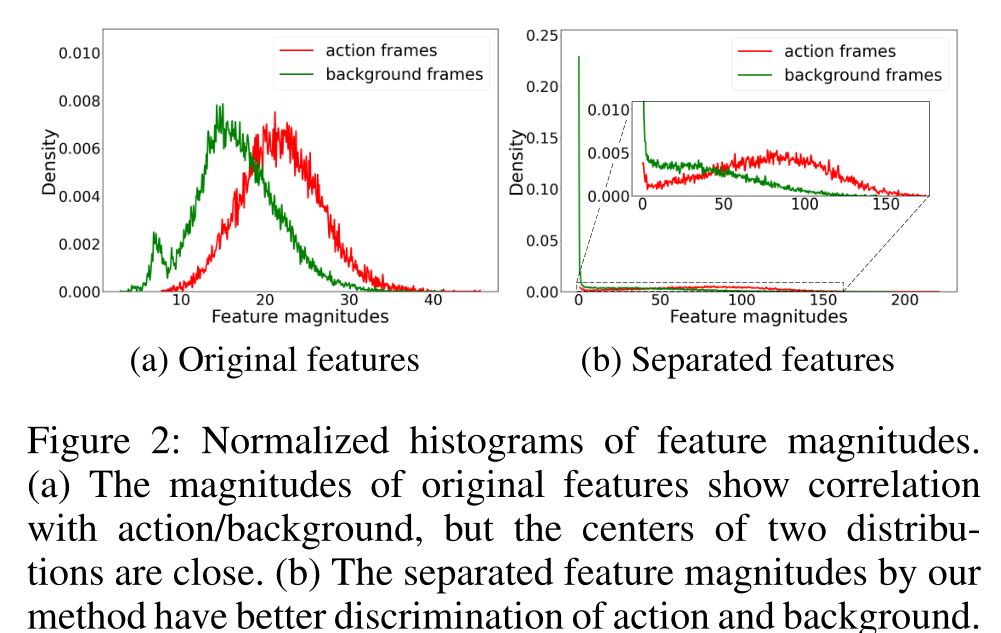
如图a中背景其实是非常动态的(理解为摄像机在动,其中的人也是在动的),图b中展现出来的一个视频中的背景是不相同的。
解决方法
论文的作者接受背景帧不一致的观察。一般来说,动作帧的特征比背景帧的特征有更大的幅度,如图a所示。这是因为动作帧需要为基本事实的动作类生成高对数。虽然特征量显示了背景和动作帧之间的识别相关性,但由于动作和背景的分布比较接近,直接使用特征量进行识别是不够的。因此,为了进一步鼓励特征幅度上的差异,作者建议通过增大动作特征的幅度和减小接近于零的背景特征的幅度来分离分布(图b)。
基于上面提出的思想提出了一个不确定性建模的方法。
具体实现
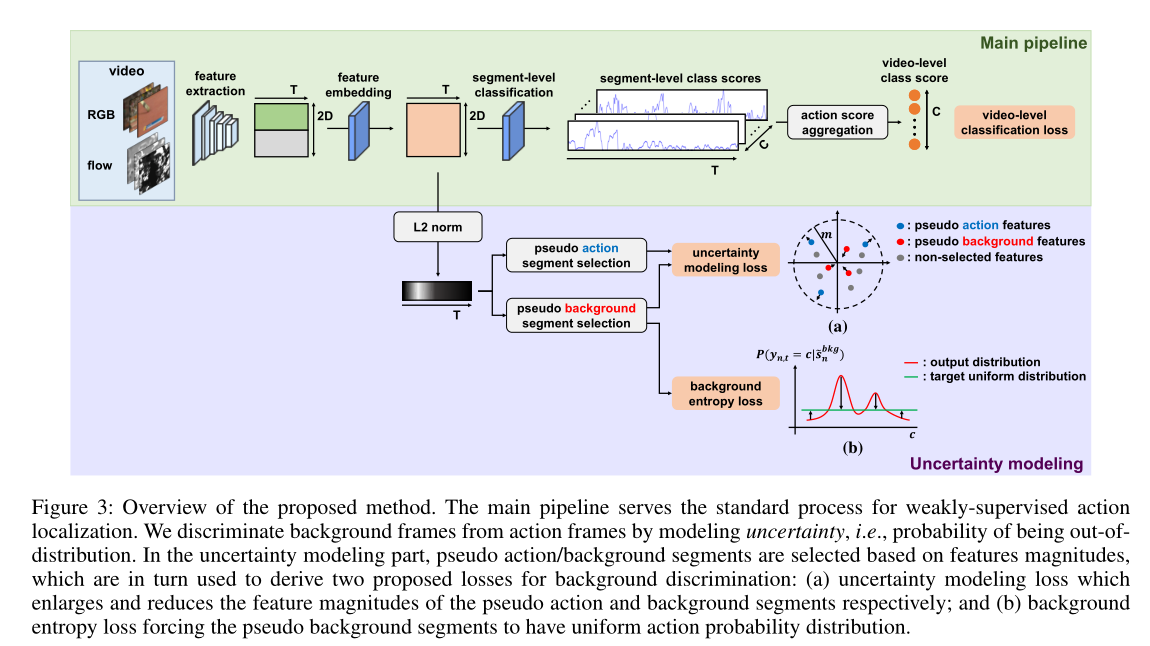
Main pipeline
Feature extraction
将视频分割成多个段,$vn=\lbrace s{n,l}\rbrace^{Ln}{l=1}$,然后进行采样使得$vn=\lbrace \tilde{s}{n,t} \rbrace^T{t=1}$。然后提取RGB特征$x^{RGB}{n,t}\in \mathbb R^D$和flow光流特征$x^{flow}{n,t}\in \mathbb R^D$,再拼接在一起$X_n=[x{n,1},…,x_{n,T}]\in \mathbb R^{2d\times T}$
特征提取这一步很简单和大多数的WTAL的方法相同
Feature embedding
为了将提取的特征嵌入到特定于任务的空间中,作者使用一个一维卷积层,然后使用一个ReLU函数。
最终得到的$Fn=[f{n,1},…,f_{n,T}]\in\mathbb R^{2D\times T}$
Segment-level classification
这一步需要得到类激活序列,使用一个分类器
其中$g_{cls}$表示线性分类器,最终得到的$A_n\in\mathbb R^{C\times T}$
Action score aggregation
遵循之前的方法,采取topk均值的方法,从而获得该类别的分数
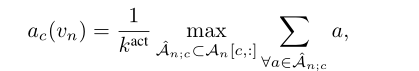
再使用softmax,可以得到对应动作c的概率
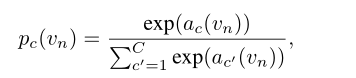
这个和之前的工作类似
Uncertainty modeling
上面部分,是基本的WTAL步骤,里面并没有考虑背景。考虑到背景帧的不约束和不一致性,我们将背景作为WTAL的out-
of-distribution和uncertainty
考虑到视频片段$\tilde{s}_{n,t}$属于第c个动作的概率,可以用链式法则(条件概率公式)将其分解为两部分
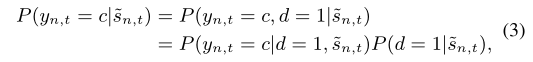
回想起条件概率公式支配的恐惧了
所以有
当然再推下去就是贝叶斯了,这个就不细说。
Uncertainty formulation
公式当中$P(y{n,t}=c|d=1, \tilde{s}{n,t})$,与一般分类任务一样,采用softmax函数进行估计。此外,有必要建模一个片段属于任何动作类的概率,也就是$P(d=1| \tilde{s}_{n,t})$的概率。
为了解决背景辨别问题。观察到动作帧的特征通常比背景帧的特征有更大的幅度(图2),我们通过使用特征向量的幅度来表达不确定性。具体来说,背景特征的幅度较小,接近于0,而动作特征的幅度较大。
然后在n个视频$( \tilde{s}_{n,t})$中的t-th段是一个动作段的概率由:
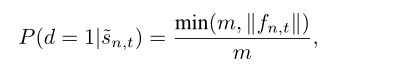
其中$f{n,t}$表示视频$\tilde{s}{n,t}$的特征,而$\lVert \cdot \rVert$是一个范数函数(这里我们使用L-2范数),m是预定义的一个特征值,从公式我们可以得到
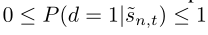
Uncertainty learning via multiple instance learning
为了只通过视频级别的标签来学习不确定性,我们借用了多实例学习的概念(Maron和LozanoPérez1998),即使用一个包(视频)而不是实例(片段)来训练模型。在这个设置中,考虑到每个未修剪的视频都包含动作帧和背景帧,我们选择伪动作/背景段来表示视频。简单来说就是选择$k^{act}$个特征幅度最大的k个片段作为伪动作片段$\lbrace \tilde{s}{n,t} |i\in S^{act} \rbrace$,选择$k^{bkg}$个片段作为伪背景片段$\lbrace \tilde{s}{n,t} |j\in S^{bkg} \rbrace$。
Training objectives
训练的损失总共有三个
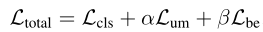
Video-level classification loss
对于多标签动作分类,我们使用二叉熵损失与标准化视频级标签
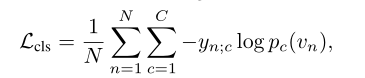
很简单的一个损失比较常见
Uncertainty modeling loss
为了学习不确定性,我们训练模型生成大特征量的伪动作片段,而生成小特征量的伪背景片段,如图3(a)所示。形式上,不确定性建模损失的形式为:
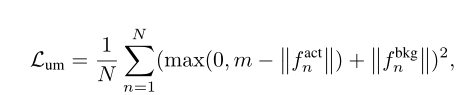
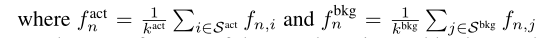
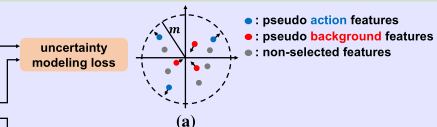
这个损失的含义是将动作特征拉的更远背景特征拉的更近,可以看这个m为特征距离,蓝色部分向m之外移动,红色部分向m之内移动。
Background entropy loss
虽然不确定性建模损失鼓励背景部分为所有动作生成低对数,但由于softmax功能的相对性,某些动作类的softmax得分可能较高。为了防止背景片段对任何动作类都有较高的softmax得分,我们定义了一个损失函数,使背景片段的动作概率熵最大化,即,背景段对动作类强制具有均匀概率分布,如图3(b)所示。损失计算方法如下:
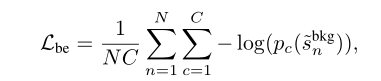
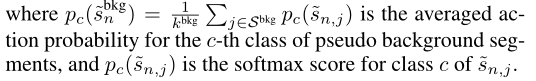
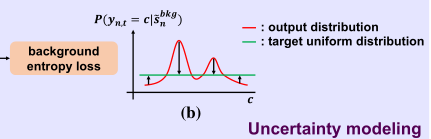
这个损失是为了防止背景在某个动作类上的softmax得分可能较高,为了将背景分数拉平而设计的一个函数。
总结
这篇文章在前人提出背景的基础上再次加深了一步研究,思想性很强不亏是微软亚洲研究院出品的,我只能称之为神仙。