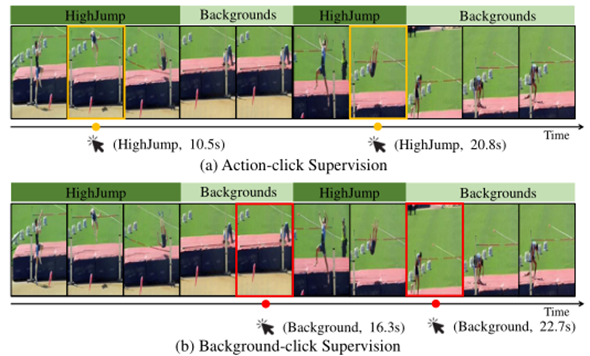
Background-Click Supervision for Temporal Action Localization
论文简介
BackTAL是2021年发表在IEEE上一篇关于弱监督时序定位的文章。论文的作者如下:

论文地址:https://github.com/VividLe/BackTAL
B站观看网站:https://www.bilibili.com/video/BV1oL4y1T7eL/
论文动机
目前弱监督时间动作定位遵循着一个潜在的假设,视频片段能够为video-level级别分类提供更多证据,尤其是动作,为video-level分类贡献更多。但是,有论文指出当背景片段与video-level更相关时,在此假设下开发的算法会陷入动作-上下文混淆困境。
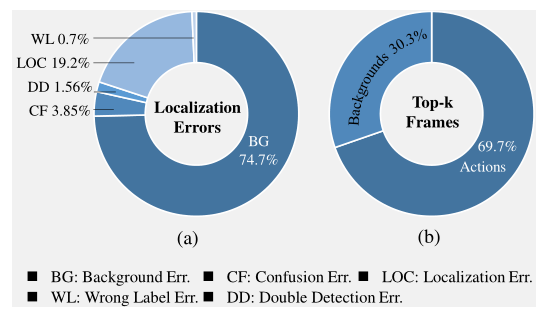
论文还分析了一下
1.定位错误的原因,主要的错误来自背景的误差。
2.给定特定的CAS,top-k帧中大部分为动作
论文框架
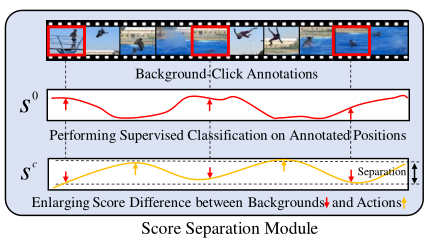
模型总体框架如下,框架重要的部分分别为Affinity Module和Score Separation Module
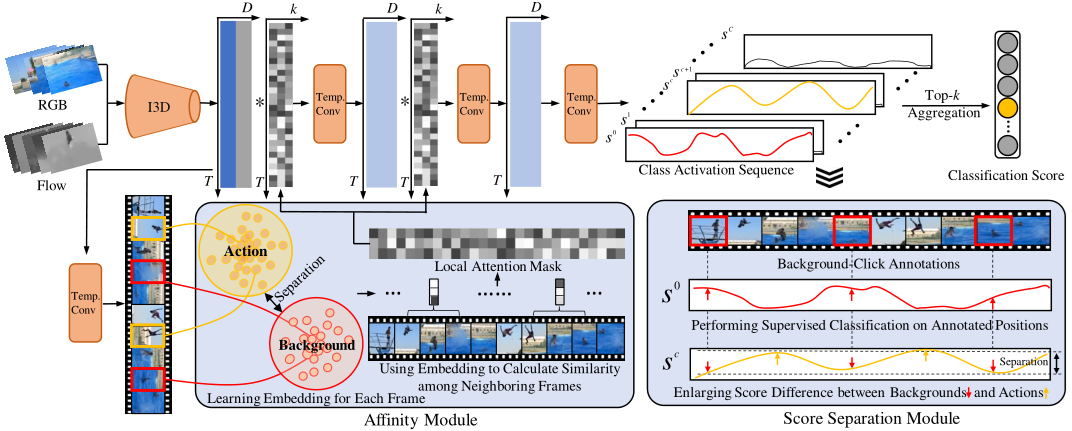
BackTAL使用三个时间卷积层来处理视频特征序列。输入视频特征$X$,获得类激活序列$S\in \mathbb R^{(C+1)\times T}$,接着使用top-k均值的方法获得视频级分类得分$s_v^c$
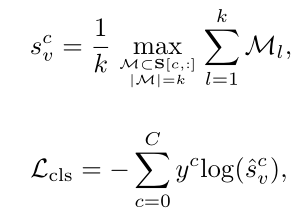
因为有背景click-level的信息,所以拥有帧级别的监督信息,可以对带注释的背景帧进行监督分类,以提高类激活序列S的质量。
考虑背景标签$b_t=1$的帧,这个帧的分类分数$S[:,t]∈R^{(C+1)×1}$,使用softmax得到$\hat{S}_t=[\hat{s}_t^0,\hat{s}_t^1,…,\hat{s}_t^c]$
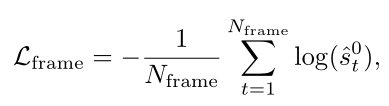
Score Separation Module
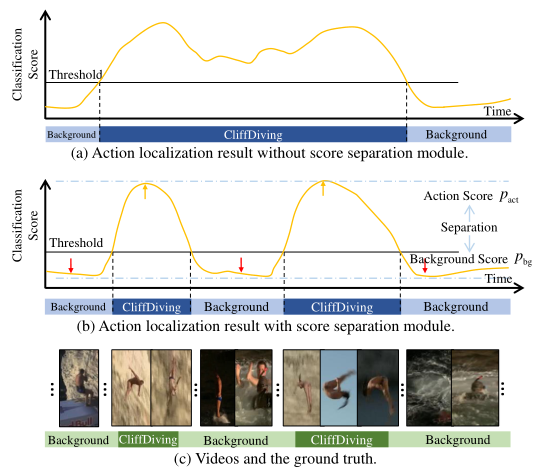
在使用top-k均值方法中,训练后期的模型总是趋向于选择相似的top-k的位置。并且对于动作和背景混淆的部分,分数也会偏高,不能很好的将背景和前景进行分离。像下图图b中红色箭头和黄色箭头所展示的。
给定一个包含$c^{th}$ 类别动作的视频,将top-k分数作为潜在动作,并计算平均分数
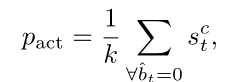
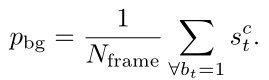
同样的,对于该视频中N_frame 注释的背景帧,计算平均分数
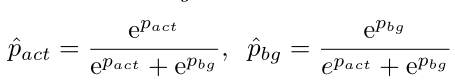
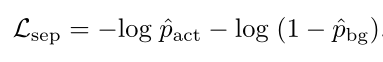
Affinity Module
Affinity Module主要基于带注释的背景帧和潜在的动作帧,充分挖掘其中的特征信息。在Affinity Module考虑到特定的一帧,可以度量它和相邻帧的亲和度,得到一帧特定的注意力权重,形成局部注意力掩码,并将其注入到卷积计算过程中。特定帧的关注权值可以引导卷积过程动态关注相关的邻居,从而产生更精确的响应。
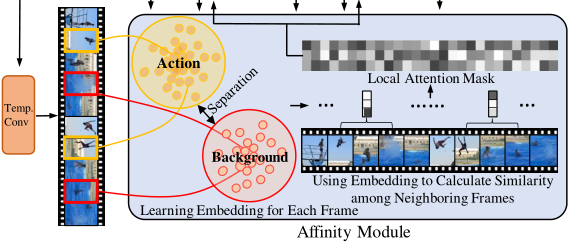
在affinity模块中,首先学习了一个嵌入空间,以从背景中区分与类无关的动作。$E=[e1,e_2,…,e_T]$,其中$e_t∈R^{D{emb}}$ ,其中每个向量$e_t$都经过L2正则对于任意两个嵌入向量,可以计算两个向量的相似度
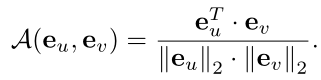
基于标注的背景帧和潜在的动作帧,可以计算两个背景帧之间、两个动作帧之间、动作和背景之间三个项的亲和力损失
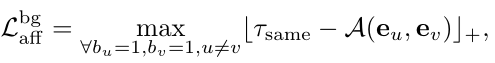
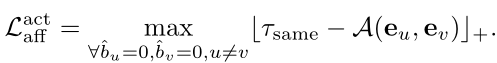
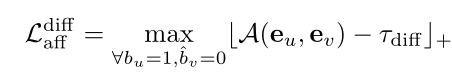
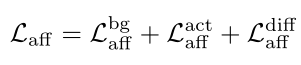
度量一帧与它的局部邻居之间的余弦相似度,嵌入向量可以区分动作帧和背景帧。

考虑一个视频特征$X\in\mathbb R^{D{in}\times T}$可以使用卷积核$H∈R^{h×D{in}×D_{out}}$ 进行处理
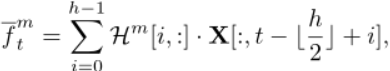
给定一个视频,我们计算每个时间位置的局部相似度,得到亲和力矩阵$a∈R^{h×T}$
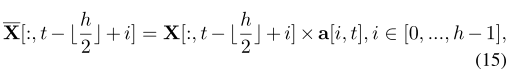
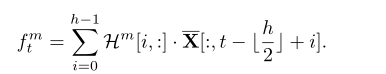
total loss
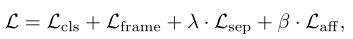
总结
论文对于click-level,将之前关注于action-click聚集到了backgroud-click上,并提出了弱监督时间动作定位的BackTAL方法。并且提出了自己的挖掘位置信息和特征信息的方法,很好的缓解了动作边界混淆的问题。