Two-Stream Consensus Network for Weakly-Supervised Temporal
文章简介
文章发表在ECCV2020上,文章提出了一个双流共识网络(TSCN),采用迭代细化训练方法,迭代更新帧级的伪真实值,并用于提供帧级监督,以改进模型训练和消除假积极动作建议。此外,文章提出了一种新的注意归一化损失,以鼓励预测的注意充当二进制选择,并促进动作实例边界的精确定位。

论文动机
1.弱监督时间动作定位(W-TAL)的目标是在视频级别监督下对未裁剪视频中所以动作实例进行分类和定位。然而由于没有帧级别的注释,W-TAL方法很难识别false positive action proposals。比如:模型可能仅通过检查场景中是否存在水来错误定位动作“游泳”。因此,有必要利用更细粒度的监督来指导学习过程。
2.另一个问题在于action proposals的生成,之前都是使用经验预设的固定阈值对激活序列进行阈值化来生成的。比如:高阈值可能导致行动建议不完整,而低阈值可能带来更多误报。
针对上面的问题,作者提出一个双流共识网络(TSCN)。TSCN采用迭代精细化训练的方法,迭代更新帧级别的标签,并用于提供帧级别监督改进的模型训练和false positive proposals消除。此外,作者提出了一种新的注意力归一化损失,以鼓励预测的注意向二进制选择一样行为,并促进动作实例边界的精确定位
思路和研究方法
提出的双流一致性网络,包括三部分:(1)利用预训练模型提取RGB和光流片段级特征;(2)使用这些RGB和光流特征分别训练两个流基模型;(3)从两流延迟融合注意序列生成帧级伪ground truth,进而为两个流基模型提供帧级监督
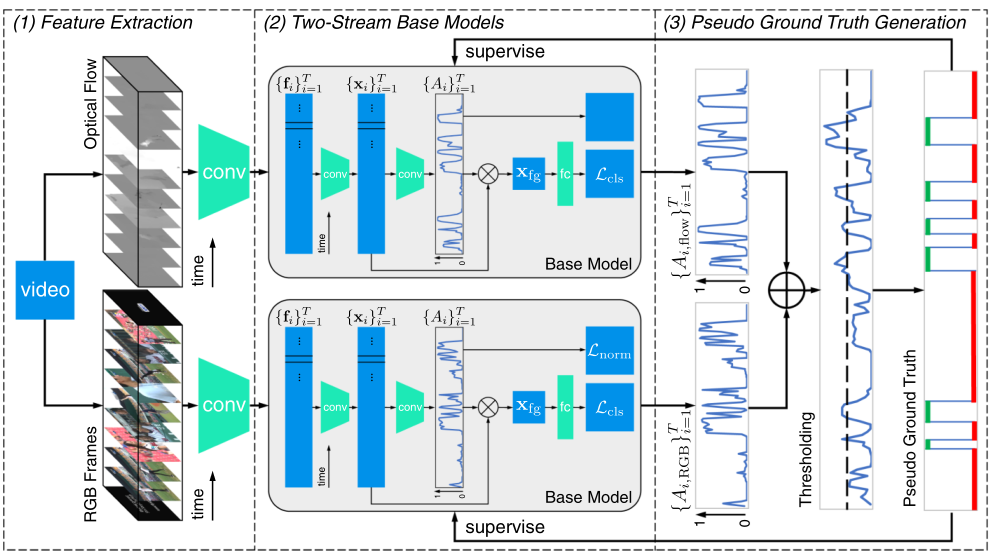
Feature Extraction
使用预训练号的网络分别从不重叠的固定长度的RGB帧片段和光流片段中提取RGB、光流特征。它们提供了相应片段的高级外观和运动信息。形式上,给定一个具有T个不重叠片段的视频,作者分别表示RGB特征个光流特征为${f{RGB}}{i=1}^T$和${f{flow} }{i=1}^T$,其中$f{RGB,i},f{flow,i}\in R^D$分别代表第$i$帧RGB和光流特征表示,$D$表示通道维数。
Two-Stream Base Models
在获得RGB和光流特征后,作者首先使用双流基础模型进行视频级的动作分类,然后用帧级别的伪标签对基础模型进行迭代细化。
两种模式特征分别输入到两个独立的基本模型中,两个基本模型使用相同的架构,但不共享参数(后面省略RGB、flow)。
作者将输入特征${fi}{i=1}^T$ 连接起来,并使用一组时间卷积生成新特征${xi }{i=1}^T$,其中$x_i\in R^D$,$D$表示输出特征维度。
由于视频可能包含背景片段,为了执行视频级别分类,作者需要选择可能包含动作实例片段,同时过滤掉可能包含背景的片段。为此,全连接(FC)层给出一个用于衡量第i个包含动作的片段的可能性的注意值$A_i \in (0,1):$
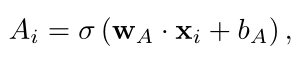
公式中$\sigma(),W_A,b_A$分别为sigmoid函数、权重向量和偏差。然后,作者对特征序列进行注意力加权池化,生成单个前景特征,并将其输入FC、softmax层,获得视频级别预测:
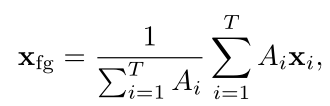
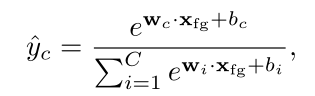
其中$\hat{y}_c$为视频包含第c个动作概率。
有了$\hat{y}c$后可以定义分类损失函数$L{cls}$ 为标准交叉熵损失:
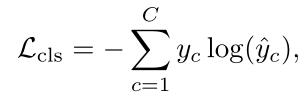
理想情况下,注意力值应为二进制,其中1表示存在动作,0表示背景。在这项工作中,作者没有使用背景分类,而是引入了注意力归一化项,以迫使注意力接近极端值:
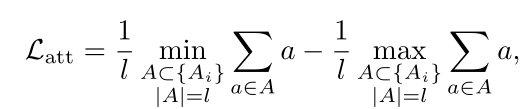
这种归一化损失旨在最大化平均top-l注意力值和平均bottom-l注意力值之间的差异,并强制前景注意力为1,背景注意力为0。
因此,基本模型训练的总损失是分类损失和注意力归一化项的加权和:
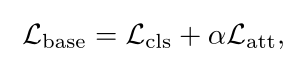
此外,通过在所有片段上滑动分类FC softmax层来生成(其实就是使用${xi }{i=1}^T$在FC层上滑动生成的),时间类激活图(T-CAM)${si }{i=}^T,s_i\in R^c$ :
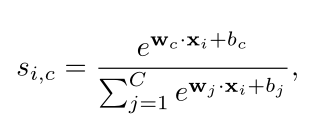
Pseudo Ground Truth Generation
作者使用帧级pseudo ground truth对两个流基模型进行迭代优化。由于没有真正的注释,既不能衡量pseudo ground truth的质量,也不能保pseudo ground truth可以帮助基础模型实现更高的性能。
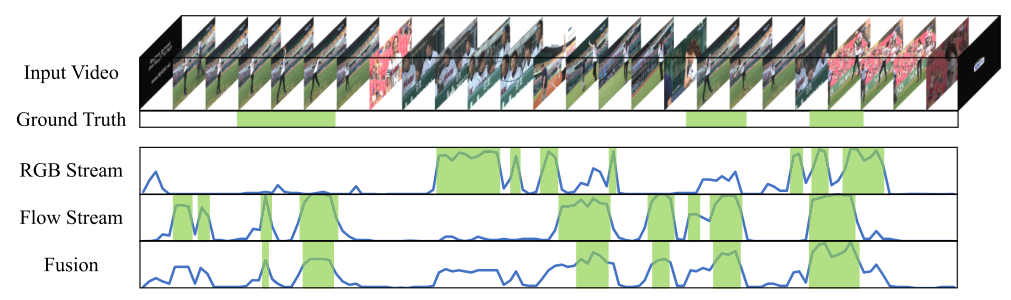
受双流后期融合的启发,作者引入了一种简单而有效的方法来生成伪地面真值。直觉上,两个流具有高激活的位置可能包含ground truth动作实例;只有一个流具有高激活率的位置很可能是只有一个流可以检测到的false positive action proposals或真实动作实例;两个流都具有低激活的位置可能是背景。
根据上诉的直觉,作者在细化迭代n时使用使用融合注意力序列${A{fuse}^{(n)} )}{i=1}^T$来生成pseudo ground truth${Gi^{(n+1)} )}{i=1}^T$用于细化迭代n+1。
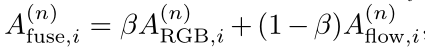
Soft Pseudo Ground Truth。直接使用融合注意力值作为伪标签的方法:$Gi^{(n+1)}=A{fuse}^{(n)}$ 。软伪标签包含片段作为前景动作的概率,但也给模型增加了不确定性。
Hard Pseudo Ground Truth。阈值注意力序列以生成二进制序列:
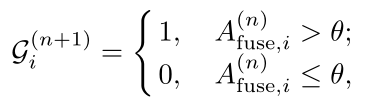
硬伪标签消除了不确定性,提供了更强的监督,但引入了超参数。
在生成帧级伪地面真值后,作者强制每个流生成的注意力序列与伪地面真值相似,具有均方误差(MSE)损失:
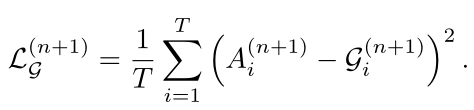
在细化迭代n+1时,每个流的总损失为
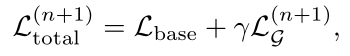
实验中最好的结果是使用Hard Pseudo Ground Truth
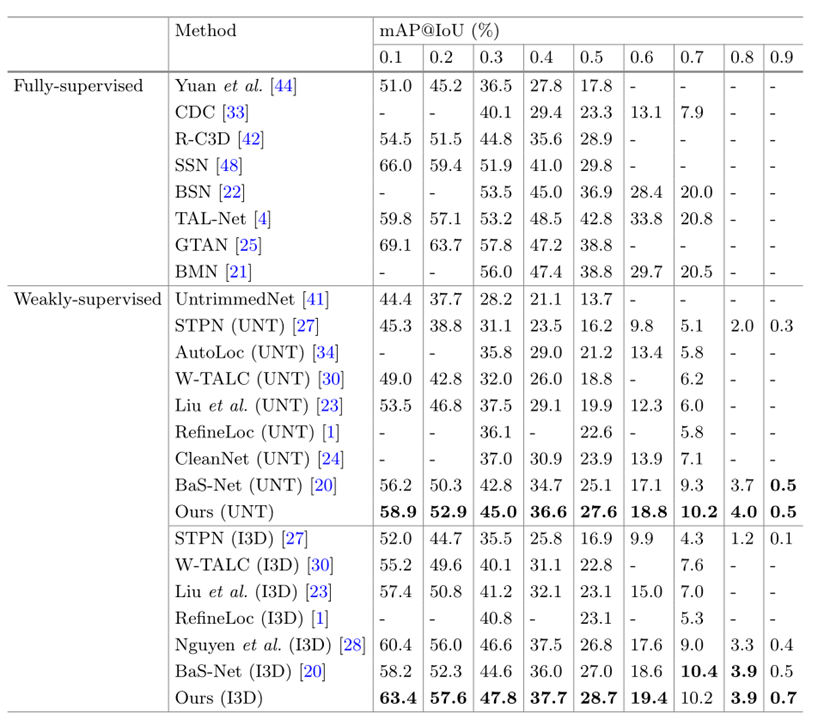
实验结果
在THUMOS’14和ActivityNet-1.2、ActivityNet-1.3上进行了实验
这里就展示了THUMOS’14的结果