Fine-grained Temporal Contrastive Learning for Weakly-supervised Temporal Action Localization
文章简介
文章发表在CVPR2022上,在这篇文章中,作者发现目前弱监督动作定位(WSAL)的任务,主要采用按分类定位的范式,这种范式忽略了视频序列之间富有成效的细粒度时间差异,在分类学习和分类到定位的适应中存在严重的歧义。为此作者提出细粒度序列距离(FSD)对比和最长公共子序列(LCS)对比,缓解分类和定位之间的任务差距。

论文动机
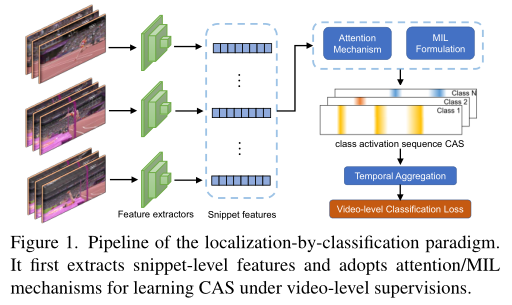
目前WSAL多采用按分类定位(localization-by-classification)的范式。他旨在生成时间类激活序列(CAS)。大多数方法采用的是使用多实例学习MIL和attention机制来训练模型,以获得具有不同类激活的片段,再通过阈值化和合并这些激活来推断最终动作定位结果。
存在问题:
(1)在弱监督中缺乏足够的注释,学习的分类器没有足够的区分性和鲁棒性,导致动作背景分离困难。
(2)分类和定位之间存在任务差距,学习的分类器通常关注易于区分的片段,而忽略定位中不突出的片段。因此,局部时间序列通常是不完整和不精确的。
为了解决上诉问题提出了Fine-grained Temporal Contrastive Learning (FTCL)。
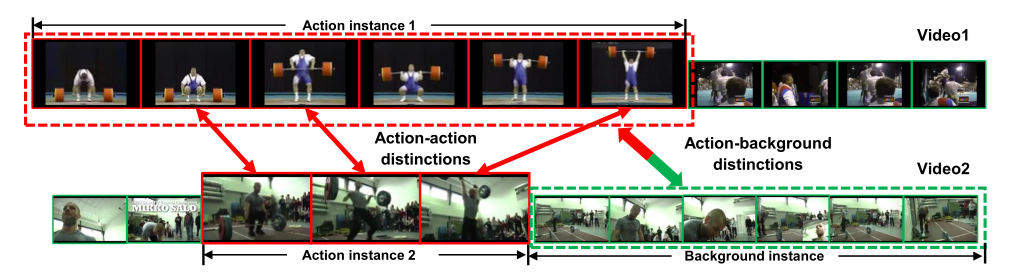
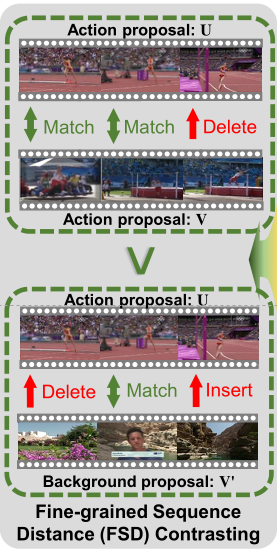
(1)计算细粒度序列距离(FSD),这个计算可以通过计算将一个序列转换为另一个序列所需的最小成本来评估两个序列在结构上是否相似 。比如下图通过Action instance1和Action instance2以及Action instance1和Background instance对比,从而实现动作和背景分离。
(2)挖掘两个包含相同动作视频之间的最长公共子序列(LCS),同一类别的不同视频序列可以通过优化LCS为探索完整的动作实例提供补充线索,比如让Action instance1和Action instance2计算LCS,可以让模型学习到动作的完整性,比如对于这个Action instance1举重最后一个帧和Action instance2对应这样就不会学丢了帧。
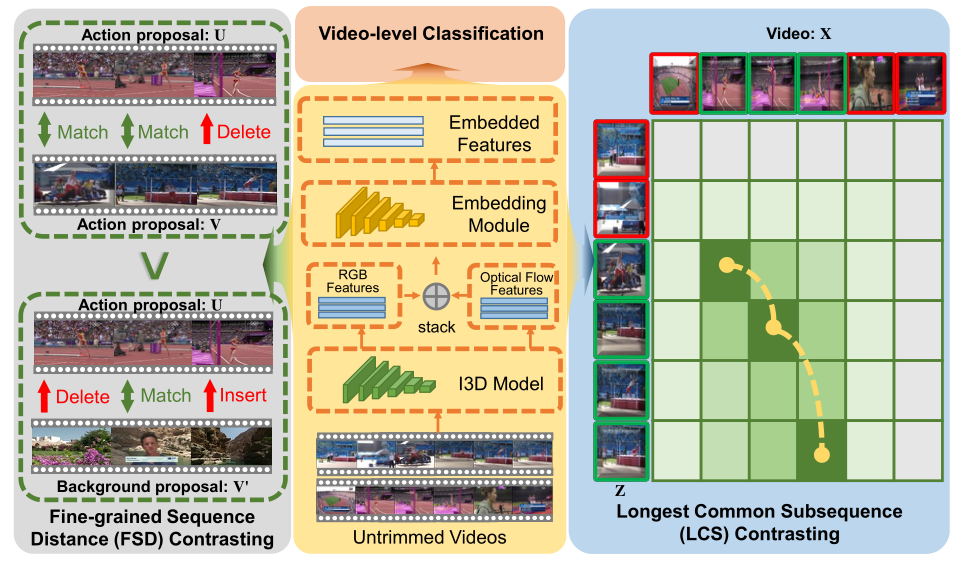
模型的总体结构图如下:
Notations and Preliminaries
给定视频X和他的标签$y \in \mathbb R^c$ 。作者将视频划分伪不重叠的T段,并使用特征提取器获得特征$X=[x_1,…,x_T]\in \mathbb R^{D\times T}$,最后输入到一个嵌入模块,用于生成$T$。
目前,现有的主流方法主要采用按分类定位的框架,改框架搜先学习将片段级别特征聚合到视频嵌入的重要性分数,然后使用视频级别标签进行动作分类:
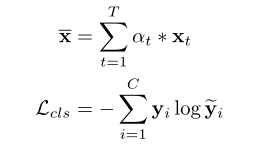
其中$\alphat=f{\alpha}(xt)$为学习到的重要性分数,将生成的视频特征进一步送入到分类器以获得预测结果$\tilde{y}=f{cls}(\bar{x})$。经过模型训练后。使用$f\alpha(\cdot)$和$f{cls}(\cdot)$来推断测试视频的片段级别激活序列CAS。
Discriminative Aciton-Background Separation via FSD Contrasting
在上述分类定位框架中,为了学习判别运动背景分类,现有的一些方法基本使用全局特征进行学习,这些方法忽略了视频之间细粒度时间差异,导致辨别能力不够。
现有的方法主要是通过测量两个序列的全局特征表示之间的向量距离来计算其相似性。而作者希望通过评估一个序列转换为另一个序列所需的最小代价来确定两个序列在结构上是否相似(如果越相似,转换的代价越小)。
本来这个问题是个np问题,但是作者使用了动态规划算法来解决这个问题,为此作者设计了可以微分的匹配、插入和删除动作符。
具体来说,通过学习到的CAS,作者科可以生成各种动作/背景proposals,其中动作proposals $U$包含高动作激活片段,而背景proposals $V$则相反。对于长度分别为M和N的两个序列, $U=[u_1,…,u_m]\in \mathbb R^{D\times M}$和 $V=[v_1,…,v_m]\in \mathbb R^{D\times N}$,它们的相似度按照如下的递归进计算:
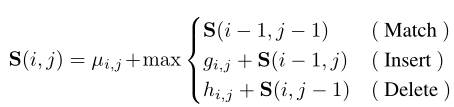
其中子序列相似度评分$S(i,j)$在第一个序列$U$的$i$位置和第二个序列$V$的$j$位置求值。$S(0,:)$和$S(:,0)$初始化为$0$。直观上,在位置$(i,j)$,如果$ui$和$v_j$匹配,应该提高序列相似度得分。如果执行插入或者删除动作相似性得分应该降低。作者学习了三种类型的残值(标量):$\mu{i,j},g{i,j}$和$h{i,j}$。
这里以$\mu{i,j}$和$g{i,j}$为例,计算公式如下:
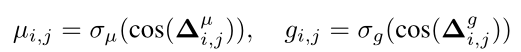
其中$\Delta^\mu{i,j}=[f\mu(ui),f\mu(vj)],\Delta^g{i,j}$类似。$f\mu(\cdot),f_g(\cdot),f_h(\cdot)$是三层全连接层。作者使用这些函数来模拟不同的动作,包括匹配、插入和删除。$\sigma\mu$和$\sigma_g$是求得残差值的激活函数。
经过上述递归计算,保证$S(i,j)$为两个序列之间的最优相似度得分。显然来自同一类别的两项动作proposals之间的相似性应大于一项动作proposals与一项背景proposals之间的相似性。通过利用这一关系,作者设计FSD对比损失如下:
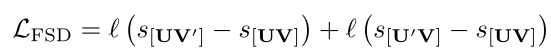
其中$l(x)$是rank loss。
Robust Classification-to-Localization Adaption via LCS Contrastingsting
WSAL的使用视频标签进行时间上的定位,这会导致分类和定位之间存在很大的任务差距。为了缓解这一任务差距,作者试图挖掘两个视频X和Z之间的最长公共子序列(LCS),从而提高学习到的动作proposals的一致性。
直觉上来说:
(1)如果两个视频动作不同,则X和Z之间的LCS长度应较小。显然,由于两种类型的动作的背景不同且存在实质性差异,两个单独视频中的片段可能高度不一致,导致LCS较短。
(2) 类似地,如果两个视频动作相同,则它们的LCS很可能很长,因为来自同一类别的动作实例由相似的时间动作片段组成。
基于上述观察 。作者也设计了一个动态规划的编程策略来计算X和Z之间的LCS。
具体来说,作者维护了一个递归矩阵$R\in\mathbb R^{(T+1)\times(T+1)}$,元素$R(i,j)$存储前缀$X_i$和$Z_j$的最长公共子序列的长度。
为了找到前缀$X_i$和$Z_j$的LCS,首先比较$X_i$和$Z_j$ 。
(1)如果它们相等,则计算的公共子序列由该元素扩展,因此$R(i,j)=R(i-1,j-1)+1$。
(2)如果它们不相等,则保留之前计算的$R(i,j)$的最大长度。
在WSAL任务中,由于一对片段不可能完全相同,即使是相同的动作类型,因此作者采用它们的相似性来计算两个序列的累积软长度(accumulated soft length )。因此,我们设计了LCS建模的递归公式:
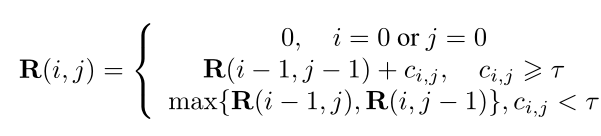
其中τ是个阈值,决定视频X的第i段和视频Z的第j段是否匹配。$c_(i,j)=cos(X_i,Z_j)$是$X_i$和$Z_j$的余弦相似性。作者最终使用交叉熵损失作为LCS的约束
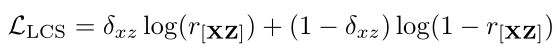
其中$r=R(T,T)$表示两个视频之间的最长公共子序列的软长度。$\delta_{xz}$ 为ground truth,代表X和Z之间是否具有相同动作类别。

Train
上述两个目标可以无缝集成到现有的WSAL框架中,并相互协作。为了优化整个模型,作者将分类损失和两个对比损失组成:
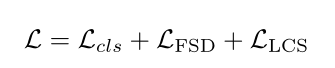
由于作者提出的方法是模型不可知和非侵入性的,通过用不同类型的损失函数和主干替换$L_cls$,这两种对比损失可以很好地与任何其他弱监督动作定位目标协作。