Weakly Supervised Temporal Action Localization via Representative Snippet Knowledge Propagation
文章简介
文章发表在CVPR2022上,作者发现许多现有弱监督时序动作定位方法试图生成伪标签以弥补分类和定位之间的差异,但目前方法通常仅利用有限的上下文信息生成伪标签。为了缓解这个问题,作者提出了一个具有代表性的片段汇总和传播框架。作者的方法试图挖掘每个视频中的代表性片段,以便在视频片段之间传播信息,从而生成更好的伪标签。

论文动机
由于在弱监督中缺乏细粒度注释,现有工作主要采用localization-by-classification的方式进行训练,使用动作类别的视频级注释训练分类器,并用于获得时间类激活图(TCAM)。再通过阈值或定位分支等方式从TCAM获得检测结果。因此,TCAM的质量决定了模型的上限。但是,分类和定位之间通常存在差异,使得模型很容易将重点放在对视频级分类贡献最大的上下文背景或区分性片段上,阻碍生成高质量TCAM。
因此有人提出了基于伪标签的方法来生成片段伪标签,以弥合分类和定位之间的差距。然而,现有方法都是使用每个片段中的信息来生成伪标签,这很难生成高
质量的伪标签。
在图1中,作者显示了两种方法的检测结果。第一种方法TSCN是一种基于伪标签的方法,而第二种方法STPN是一种不使用伪标签的简单基线模型。正如我们所看到的,即使TSCN和STPN相比获得了很大的增益,但这两种方法都没有成功地检测到橙色框中的困难动作实例,该框仅显示运动员的部分身体。显然,由不准确的TCAM生成的伪标签也不准确。相反,对于简单的例子,例如蓝色框中的一个,这两种方法都能准确地检测到它。
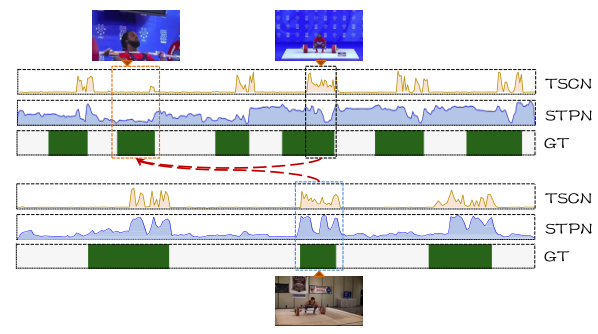
为此作者引入上下文信息来生成伪标签。具体来说,作者以视频内和视频间的方式传播这些代表性片段(图中的黑色和蓝色方框)的知识,以促进伪标签的生成,特别是对于那些困难的片段(图中的橙色方框)。
作者提出了一个具有代表性的片段汇总和传播框架。作者的方法试图挖掘每个视频中的代表性片段,以便在视频片段之间传播信息,从而生成更好的伪标签。对于每个视频,以视频内和视频间的方式传播其自身的代表片段和来自存储库的代表片段以更新输入特征。伪标签是由更新特征的时间类激活映射生成,以纠正主分支的预测
作者的方法概述 如下:
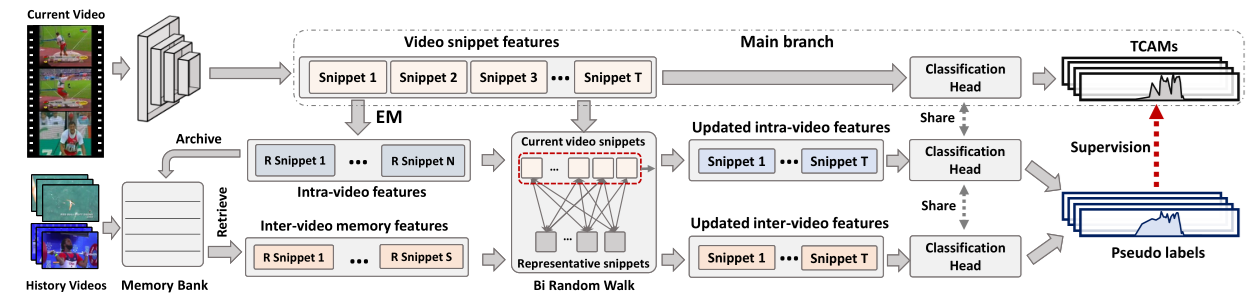
Feature extraction
给定一段视频,作者首先把它分为一些列不重叠片段。接下来,作者利用固定权重的backbone网络,在Kinetics-400数据集上预训练I3D模型,将外观(RGB)和运动(光流)信息编码为d=2048维特征。I3D特征通过卷积层编码到潜在嵌入F∈R^(l×d)中,其中l是视频的片段数。作者取F作为模型的输入。
Classification head
分类头用于生成TCAM,它可以是任何现有的WSTAL方法。为了生成高质量的TCAM并改进作者方法的下限,作者使用了最新的FAC-Net作为分类头(作者经过一定的修改),因为它具有简单的管道和良好的性能。
Representative Snippet Summarization
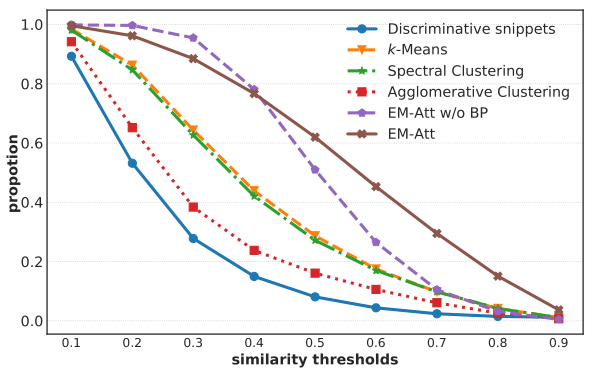
获得代表性片段的简单方法是选择预测得分高的片段,即辨别性片段。然而,如图所示,即使经过大规模的预训练,辨别性片段和同类别的其他片段之间的相似度通常较低。直观地说,代表性片段应该能够描述同一类的大多数片段,从而起到联系同一类片段进行知识传播的桥梁的作用。因此,将辨别性片段的信息直接传播到其他片段是无效的。
作者提出对视频片段的表示方式进行总结,得到每个视频的辨别性片段。在图中,通过聚类视频片段特征(例如,k均值、谱聚类和凝聚聚类),使用聚类中心作为代表片段,取得了更好的性能。实验表明,使用聚类方法总结代表性片段对于提高高检测性能有重要意义。
在这项工作中,作者使用期望最大化(EM)注意力来生成每个视频的代表性片段。EM注意力使用基于高斯混合模型(GMM)的特殊EM算法。具体来说,采用分离的GMM来捕获每个视频的特征统计信息,并将$f_i\in \mathbb R^d$($F$的第$i$个片段特征)的分布建模为一个高斯线性组合,如下所示:
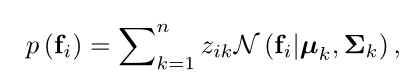
其中$n$为高斯函数的个数,$\muk\in\mathbb R^d,\sum_k\in\mathbb R^{d\times d},Z{ik}$分别表示第$k$个高斯函数的均值、协方差矩阵和权重。作者用单位矩阵I替换了协方差,在后续的方程中去掉它。(其实这里的$\mu$是高斯函数的平均值,但是也可以理解为)
如图(顶部)所示,EM注意力从随机初始化的均值$\mu^{(0)}\in\mathbb R^{n\times d}$开始。在第$t$次迭代中,首先执行E步骤,计算高斯的新权重$Z^{(t)}\in\mathbb R^{t\times n}$为:
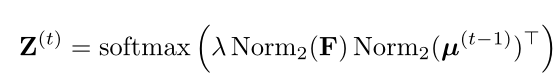
其中$\lambda$表示一个超参数,用于控制分布的平滑度。$Norm2 (F)$沿F的每一行的$l2-norm$。softmax操作沿$Z$的每一行都执行。因此,$Z^{(t)}{ik}$表示片段特征$f_i$由第k个高斯函数生成的概率。
在E步骤之后,M步骤将平均值μ进行更新为:
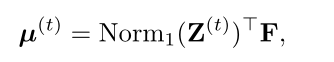
其中$Norm_1(Z^{(t)})$表示$Z^t $按照列进行$l_1$ 归一化。可以看到公式更新均值实验特征F的加权求和。归一化确保更新后的$\mu$与$F$位于相同的嵌入空间中。因此,交替执行上述两个等式以非局部但更有效的方式捕获视频的全局上下文,这是因为均值$\mu^{(t)}\in\mathbb R^{n\times d}$ 的尺寸比视频特征$F\in\mathbb R^{l\times d}(l>>n)$小的多。
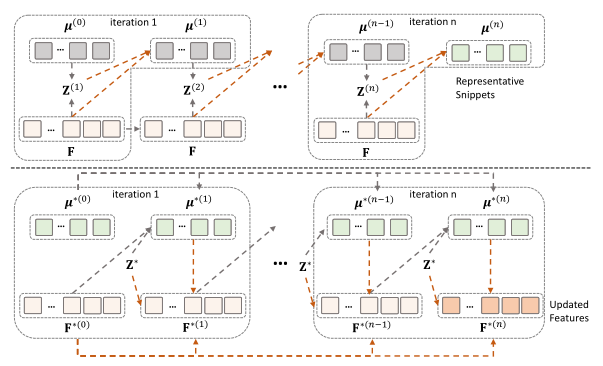
作者在网络中集成了两个EM迭代,以获得有希望的代表性片段(即$\mu^{(2)}$ )。作者通过标准反向传播更新初始化均值。此外,当作者用一个(半)正交矩阵初始化$\mu^{0}$时,即使固定了初始化的均值(即图中的EM-Att w/o BP),获得的代表性片段也比其他聚类方法的聚类中心更具代表性。当作者通过标准反向传播(即图中的EM-Att)更新初始均值$\mu^{0}$时,它们可以捕获数据集的特征分布并实现最佳性能。为了使方程清晰并避免混淆,我们将在线计算的代表性片段表示为$\mu^{(a)}$ 。
Representative Snippet Memory Bank
在获得每个视频的代表性片段后,作者使用一个存储库来存储每个类的所有高置信度视频的代表片段。作者认为不同的视频可能包含相同的动作实例,但是具有不同的外观。因此,通过存储库以视频间的方式传播代表性片段,可以利用每个类的许多视频的巨大变化,帮助网络识别那些困难的动作实例。
具体来说,作者维护了两个记忆表,分别存储代表性片段的特征及其分数。我们将代表性片段的内存表表示为$M\in\mathbb R^{c\times s\times d}$,其中c是类的数量,s表示每个类的内存插槽(代表性片段)的数量。给定视频的代表性片段,作者利用分类头中的动作分类器来获得它们的类预测。然后,将它们真实类的预测分数与存储表M中的代表性片段进行比较,预测分数较高的片段被归档到存储表M。同时,分数存储表中的相应分数也被更新。总之,作者只将分数高的代表性片段保留在内存表中。为了区别于在线代表性片段$\mu^{(a)}$ ,将离线代表性片段表示为$\mu^{(e)}$ 。
Representative Snippet Propagation
给定在线和离线代表性片段$\mu^{(a)}$和$\mu^{(e)}$ ,一个挑战是如何将代表性片段传播到当前视频的片段特征F。直观地说,一种直接的方法是使用亲和力$Z^∗$(∗ 是a或e),进行随机游动操作作为$Z^∗ μ^∗$ 。 实际上,作者希望更新后的特征不会偏离视频特征F太远。因此,传播过程可以公式化为$F^∗=\omega⋅Z^∗ μ^∗+(1-\omega)⋅F$,其中$\omega$表示控制特征传播和原始特征之间权衡的参数。
然而,即使代表性片段与同一类的大多数片段具有高度相似性,通过一次传播来完全传播代表性片段的知识也是不切实际的。作者发现,具有代表性的片段$\mu^$和视频特征F实际上构成了一个完整的二部图,其亲和力由$Z^∗$表示。因此,作者提出了一个*二部随机游走(BiRW)模块,以实现多次传播,将代表性片段的知识完全融合到视频片段特征中。
BiRW中有多次迭代。在第$t$次迭代中,传播过程公式如下:
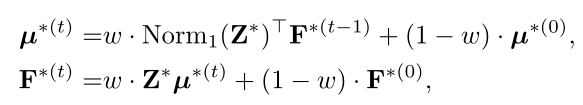
其中其中$F^{(0)}$和$\mu^{(0)}$分别是视频片段特征$F$和代表片段 。$\mu^{(a)}$和$\mu^{(e)}$如图(底部)所示,上述公式也可以被视为EM过程,它固定了亲和力$Z^*$交替更新$F$和$\mu^∗$ 。因此,代表性片段不仅用于传播代表性知识,而且还作为桥梁在F的特征之间传播知识。由于其代表性,它们可以更好地在同一类的特征之间传播信息。这个过程可以多次进行,以充分融合代表性片段的知识。
为了避免展开计算图引起的梯度消失或爆炸,作者使用近似推理公式
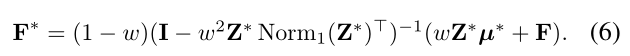
注意,我们使用等式(6)分别传播关于$\mu^{(a)}$和$\mu^{(e)}$的知识,而不是连接$\mu^{(a)}$和$\mu^{(e)}$来传播代表性片段。该设计目的是防止从F的同一视频中提取的在$\mu^{(a)}$传播中占主导地位。因此,在代表性片段传播后,我们分别获得更新的视频内特征$F^a$和更新的视频间特征$F^e$。
Training Objectives
给定原始视频片段特征$F$和更新后的特征$F^a,F^e$,我们将其输入三个具有共享参数的并行分类头,分别输出其TCAM $T$、$T^a$和$T^e$。对TCAMs进行加权求$T^a$和$T^e$和,获得包含视频内和视频间代表性片段知识的TCAM $T^f$。作者将$T^f$作为在线伪标签来监控TCAM $T$
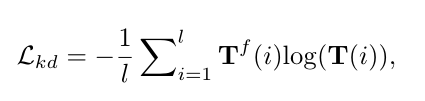
其中t是片段数。总损失是损失$L{kd}$、三个分类头的视频分类损失$L{cls}$和只应用于主分支的注意力归一化损失$L_{att}$的总和。
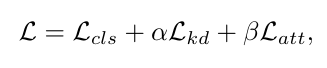
其中α和β是平衡参数。
注意力归一化损失$L_{att}$在TSCN中提到过
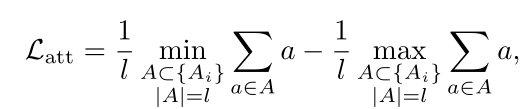
参考: