python使用opencv提取光流
光流flow特征中包含了一个视频当中运动相关的信息,在视频动作定位当中光流特征使用的比较多,所以记录一下提取光流特征的方法。
使用的方法是TVL1方法,最终提取的光流图片还可以配合I3D模型进行特征的提取。光流的计算先需要将视频一帧一帧提取出来,然后再通过连续两帧之间的差异进行计算。
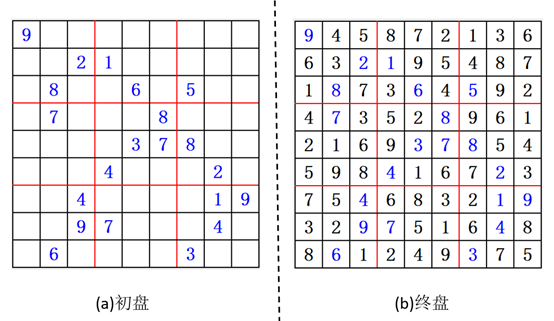
数独游戏是一款古老的智力游戏,据说最早可以追溯到中国古代的“河图洛书”,但是真实可查的是在18世纪数学家欧拉等人发明了“拉丁方阵”等成为数独的最早的样子,后来经过日本的改进逐渐成为现代的数独游戏[1]。
数独游戏一共有$9 \times 9$个单元格子,在数独游戏当中,玩家需要根据已有的数字去推理出所有的剩余空格的数字,并且要保证 $9 \times 9$的单位格子中每一行、每一列以及每个$3 \times 3$的九宫格内的数字不重复。数独游戏在开始的适合叫做初盘(如图1(a)所展示),包含数字和空格,当游戏成功完成时的状态叫终盘(图1(b)所展示),只有填写完成的数字。
BackTAL是2021年发表在IEEE上一篇关于弱监督时序定位的文章。论文的作者如下:

论文使用自监督的方法来改造半监督行为建议区域生成。
作者专门设计了一个Self-supervised Semi-supervised Temporal Action Proposal (SSTAP) 网络结构,后面简称SSTAP。SSTAP包含两个分支temporal-aware semi-supervised branch 和relation-aware self-supervised branch,简单理解就是一个半监督分支和一个自监督分支。半监督分支是加入特征偏移和特征翻转在the mean teacher frame-work上,自监督分支则是定义了两个任务masked feature reconstruction 和 clip-order prediction




