Activity之间通讯
Activity之间经常需要传输数据,我们常用的方法就是使用Intent
这个练习需要你定制toast消息,改在屏幕顶部而不是底部显示弹出消息。这需要使用Toast 类的setGravity方法,并使用Gravity.TOP重力值。具体如何使用,请参考Android开发者文档。
参考官方给定的Toast例子结合对setGravity函数的讲解
我们只需要在QuizActivity中的函数中填入下属代码即可
1 | mTrueButton = (Button) findViewById(R.id.true_button); |
参考:
Activity是android当中重要的内容,每个Activity实例都有其生命周期。在其生命周期内,Activity在运行、暂停、停止和不存在这四种状态间转换,每次状态转换时,都有相应的Activity方法发消息通知activity。Activity 类提供六个核心回调:onCreate()、onStart()、onResume()、onPause()、onStop()、onDestory(),官方给出的状态变化以及函数调用如下图所展示
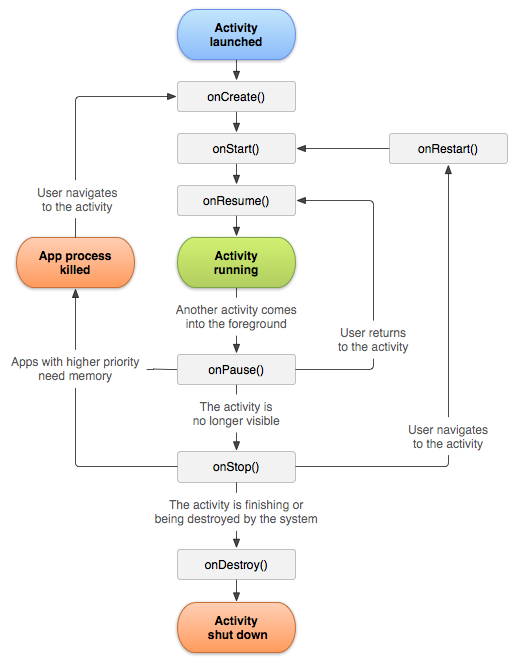
但是我感觉比较好理解的是《Android编程权威指南》中的图解
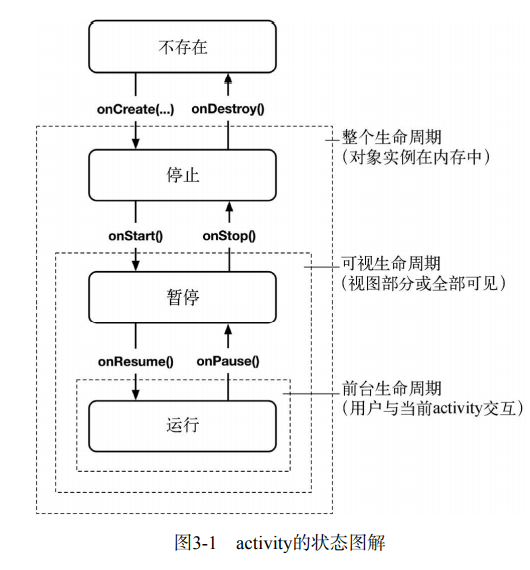
可以根据内存中有没有activity的实例,用户是否看得到,是否活跃在前台(等待或接受用户输入中)等这些作为判断,调用了那些函数。完整总结如下表所示。
| 状态 | 有内存实例 | 用户可见 | 处于前台 |
|---|---|---|---|
| 不存在 | 否 | 否 | 否 |
| 停止 | 是 | 否 | 否 |
| 暂停 | 是 | 是或者部分 | 否 |
| 运行 | 是 | 是 | 是 |
matplotlib是最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB进行构建。
👉官网地址:https://matplotlib.org/
matplotlib能画的图有折线图、散点图、柱状图、直方图、饼状图等,所以本次主要讲解这几张图,注意本次代码主要使用官方文档上的面向对象风格,当然使用pyplot风格也是同样可以实现的
matplotlib是最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建。最近做了很多关于数据分析的题目,对于画图感觉掌握的不熟练所以特地来学习一下。
👉官网地址:https://matplotlib.org/
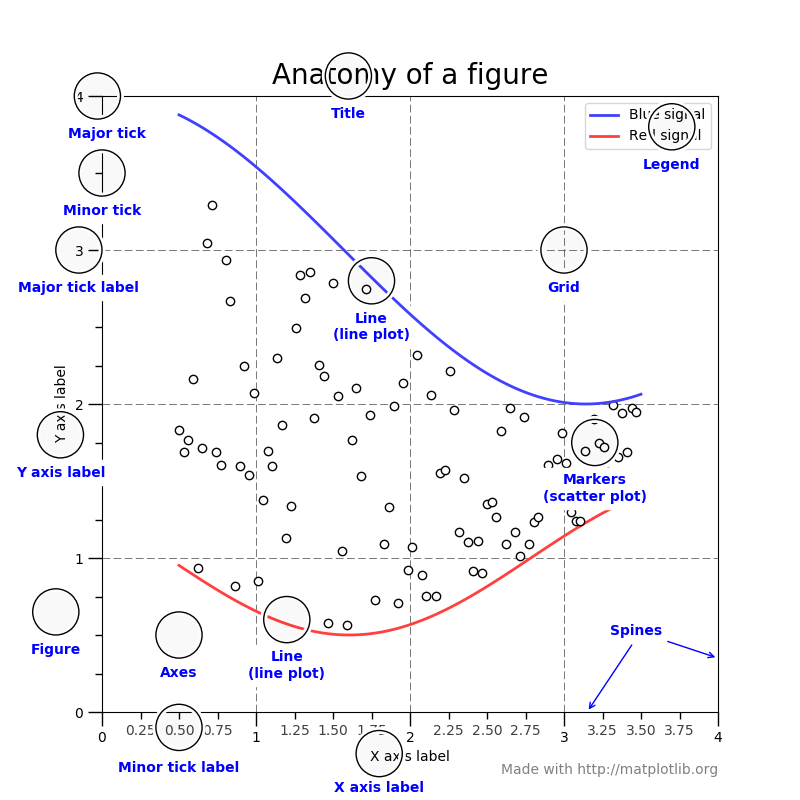
下面这张图是 Matplotlib 图形的组成部分。主要有title、tick、legend、label这类的东西,所以本次也主要从这些出发。
弱监督视频动作定位中,先前的方法聚合帧级别的类分数,以产生视频级别的预测并从视频级别的动作中学习。此方法无法完全模拟问题,因为背景帧被迫错误地分类为行动类别,无法准确预测视频级标签。
设计了背景抑制网络(BaSNet),该网络引入了背景的辅助类,并具有带有非对称度量训练策略的两分支权重共享体系结构。这使BaSNet可以抑制来自背景帧的激活,从而提高定位性能。广泛的实验证明了BaSNet的效率及其在最流行的基准THUMOS14和ActivityNet上优于最新方法的优越性
BaSNet:有两条分支Base branch and Suppression branch
未修剪视频中的时间动作定位(Temporal action localization,TAL) 最近获得了巨大的研究热情,但是TAL目前并没有无监督的的方法出现,所以本论文提出了第一种无监督的TAL方法。
为了解决动作定位,两步进行 “聚类+定位”迭代过程。
聚类步骤为定位步骤提供了noisy的伪标记,而定位步骤提供了时间共关注模型,从而提高了聚类性能,这两个过程相辅相成。
在弱监督下 TAL可被视为我们ACL的直接扩展模型。
从技术上讲,我们的贡献有两个方面:
从视频级标签或伪标签中学习的时间共同注意模型,无论是针对特定类别还是不可知类别的 以反复强化的方式;
为ACL设计了新的loss,包括action-background separation loss和cluster-based triplet loss。
最终的成绩:
针对20种动作THUMOS14和100种 行动ActivityNet-1.2。 在两个基准上,建议 ACL的模型具有强大的性能,甚至可以与最新的弱监督方法相比。 例如,以前最好的弱监督 在THUMOS14上的mAP@0.5下,模型达到了26.8%, 我们的新记录分别为30.1%(弱监督)和25.0% (无监督)。
[toc]
摘要:在计算机视觉中,时间动作定位是视频理解中最关键也是最具挑战性的问题之一。由于其广泛的应用,近年来引起了广泛的关注日常生活应用。时间动作定位技术已经取得了很大的进展,特别是最近深度学习的发展。而且在未裁剪的情况下,现在需要更多的时间动作定位视频。在这篇论文中,我们的目标是调查最新的技术和模型的视频时间行动定位。主要包括相关技术、一些基准数据集和评价时间动作定位的度量。此外,我们从两个方面总结了时间动作定位各方面:全监督学习和弱监督学习。并列举了几部具有代表性的作品并比较他们各自的表现。最后,对其进行了深入分析,并提出了发展前景研究方向,并总结调查。
关键词:动作检测,计算机视觉,全监督学习,时间动作定位,弱监督学习。
随着视频数量急剧的增长,视频理解成为了计算机视觉领域的一个热点问题和具有挑战性的方向。这个视频理解发个信包括许多子研究方向,包括在夏威夷,被CVPR举办的ActivityNet 挑战2017,这个网络一共提出了5个任务。
在最近的调查中,我们关注的是时间动作定位,也就是上面列出的第四个。它需要检测包含目标动作的时间间隔。对于长时间的未裁剪的视频,时间动作定位主要解决两个任务,识别和定位。特别是,a)动作发生的起始时间和终止时间,b)每个提案的类别是什么属于(如挥手、爬山、扣篮)。当然,一个视频可能包含一个或多个行动剪辑(action clips),所以时间动作定位是要开发模型和技术来提供计算机视觉应用所需要的最基本的信息:动作是什么,动作什么时候发生?我们将这个任务作为动作定位,或时间动作定位,或动作检测。
虽然动作识别和动作本地化都是视频理解里面很重要的任务,但是时间动作定位比动作识别更加具有挑战性。动作识别和动作定位的关系和图像检测类似于图像识别和图像检测。但是由于时间连续信息(temporal series information),时间动作定位比图像检测更见困难。困难主要来自以下几个方面:a)时间信息,由于1维时间连续信息,时间动作定位不能使用静态图片信息,它必须结合时间连续信息。b)与目标检测不同的是,边界对象通常是非常清晰的,所以我们可以为对象标记一个更清晰的边界框。然而,可能没有关于动作的确切时间范围合理定义,所以,不可能给一个动作开始和结束的准确边界。c)大的时间跨度,时间动作片段的跨度可以是非常大的,比如,挥手可能只几秒钟但是攀岩和骑自行车能够持续十几秒。它们时间跨度在长度上的不同,是的提取检测(extract proposals)很困难。另外,在开放的环境当中,这里也又许多问题,例如多尺度,多目标和相机移动。
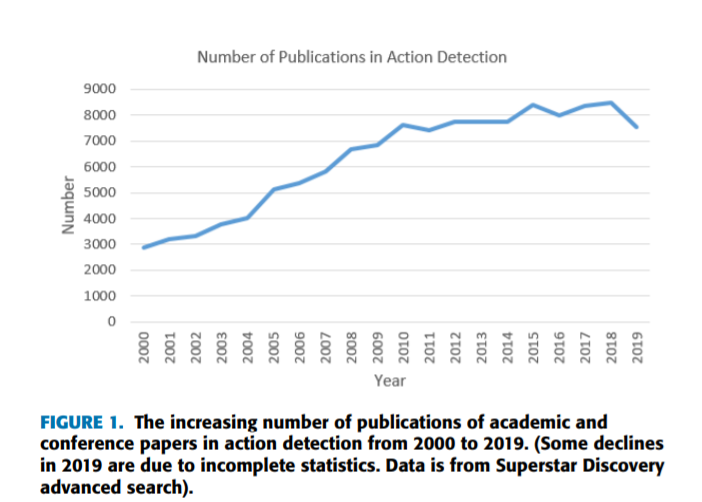
时间动作定位非常贴近我们的生活,它具有广泛的应用前景和社会价值在视频概况(video summarization)、公共视频监控、技能评估和日常生活安全。所以它在最最近几年得到了广泛的关注。与“动作检测”有关的出版物总数约为324127份,近二十年来包括书籍、期刊、论文、会议论文、专利和一些科技成果。下面我们主要分析出版学术和回忆论文的趋势动作检测,如同图1所示
本调查旨在帮助对时态动作本地化感兴趣的初学者。它提供一个概括动作定位的方法和最新进展,本文余下部分组织如下。